tdwg-content
Threads by month
- ----- 2026 -----
- June
- May
- April
- March
- February
- January
- ----- 2025 -----
- December
- November
- October
- September
- August
- July
- June
- May
- April
- March
- February
- January
- ----- 2024 -----
- December
- November
- October
- September
- August
- July
- June
- May
- April
- March
- February
- January
- ----- 2023 -----
- December
- November
- October
- September
- August
- July
- June
- May
- April
- March
- February
- January
- ----- 2022 -----
- December
- November
- October
- September
- August
- July
- June
- May
- April
- March
- February
- January
- ----- 2021 -----
- December
- November
- October
- September
- August
- July
- June
- May
- April
- March
- February
- January
- ----- 2020 -----
- December
- November
- October
- September
- August
- July
- June
- May
- April
- March
- February
- January
- ----- 2019 -----
- December
- November
- October
- September
- August
- July
- June
- May
- April
- March
- February
- January
- ----- 2018 -----
- December
- November
- October
- September
- August
- July
- June
- May
- April
- March
- February
- January
- ----- 2017 -----
- December
- November
- October
- September
- August
- July
- June
- May
- April
- March
- February
- January
- ----- 2016 -----
- December
- November
- October
- September
- August
- July
- June
- May
- April
- March
- February
- January
- ----- 2015 -----
- December
- November
- October
- September
- August
- July
- June
- May
- April
- March
- February
- January
- ----- 2014 -----
- December
- November
- October
- September
- August
- July
- June
- May
- April
- March
- February
- January
- ----- 2013 -----
- December
- November
- October
- September
- August
- July
- June
- May
- April
- March
- February
- January
- ----- 2012 -----
- December
- November
- October
- September
- August
- July
- June
- May
- April
- March
- February
- January
- ----- 2011 -----
- December
- November
- October
- September
- August
- July
- June
- May
- April
- March
- February
- January
- ----- 2010 -----
- December
- November
- October
- September
- August
- July
- June
- May
- April
- March
- February
- January
- ----- 2009 -----
- December
- November
- October
- September
- August
- July
- June
- May
- April
- March
- February
- January
- ----- 2008 -----
- December
- November
- October
- September
- August
- July
- June
- May
- April
- March
- February
- January
- ----- 2007 -----
- December
- November
- October
- September
- August
- July
- June
- May
- April
- March
- February
- January
- ----- 2006 -----
- December
- November
- October
- September
- August
- July
- June
- May
- April
- March
- February
- January
- ----- 2005 -----
- December
- November
- October
- September
- August
- July
- June
- May
- April
- March
- February
- January
- ----- 2004 -----
- December
- November
- October
- September
- August
- July
- June
- May
- April
- March
- February
- January
- ----- 2003 -----
- December
- November
- October
- September
- August
- July
- June
- May
- April
- March
- February
- January
- ----- 2002 -----
- December
- November
- October
- September
- August
- July
- June
- May
- April
- March
- February
- January
- ----- 2001 -----
- December
- November
- October
- September
- August
- July
- June
- May
- April
- March
- February
- January
- ----- 2000 -----
- December
- November
- October
- September
- August
- July
- June
- May
- April
- March
- February
- January
- ----- 1999 -----
- December
- November
- October
- September
- August
November 2010
- 37 participants
- 44 discussions

13 Nov '10
I'm going to start this post with two comments about RDF. I think some
people think they have a phobia of RDF (I know that I did at first).
What I really think is that they have a phobia of RDF represented as XML
or RDF represented in N3 notation. This point has been made before: RDF
is a system for describing properties of and relationships among
resources (i.e. things that can be assigned identifiers) but it does not
have only one particular way that these properties and relationships
must be specified. It is perfectly correct to represent RDF entirely in
pictures (i.e. as an RDF "graph", see http://www.w3.org/TR/rdf-primer/
and ignore all of the text - just look at the figures). RDF graph
notation wouldn't be of much use to a computer, but that graph could
easily be translated into one of the other notations (XML or N3) and
then a computer would understand it perfectly. Since RDF is something
that is specifically designed to represent relationships among classes
of resources, it is the perfect thing to clearly lay out what we mean
when we have a discussion of the sort that we are having here. One of
the reasons why I am so keen to make diagrams of the sort I posted in
the first message in this series is because once you have the diagram,
it is a relatively simple matter to change the shapes of the boxes and
add arrows instead of triangles or lines with crow's feet and voila! you
have an RDF graph. It then becomes an academic exercise to have an RDF
model in XML or whatever format you like. I am of the opinion that we
are actually pretty close to a consensus about what the diagram should
be, which means that we are also pretty close to a simple RDF model for
Darwin Core.
The other comment about RDF is that we need to work out a basic model
now. Partly this is because there are already several people who have
been contributing to this discussion who are already writing RDF or who
intend to do so in the near future. If we have any delusions about
doing even the most simple kind of machine reasoning in the future, we
all need to be using the same basic diagram (i.e. model). The other
reason why we need to work this out now is that if we don't, we will
impede the process of utilizing GUIDs/Persistent Identifiers. The draft
TDWG GUID Applicability Statement
(http://www.tdwg.org/stdtrack/article/download/150/51 recommendation 10)
says clearly that a proper GUID should be able to be dereferenced to
provide an RDF/XML representation (did I use "dereferenced" right,
Bob?). If we don't agree on how to represent the classes of resources
that are of interest to the DwC community in RDF then we are setting up
the situation where TDWG makes a recommendation (on how GUIDs are
implemented) that is impossible for people to follow. I believe that it
is best to settle on a basic model now rather than at an indefinite
point in the future for this reason.
Having given this rationale, I'm going to talk about how we look at
classes and types in Darwin Core and how the need for an RDF
representation of DwC should influence our view on this topic. In
Darwin Core as it stands (see the "Audience" section of
http://rs.tdwg.org/dwc/terms/index.htm) classes are simply categories
that group terms that describe instances of the class. The description
specifically states that the terms are intended to be properties of the
class (i.e. properties of instances of the class). When DwC terms are
used as column headings in a database table, there isn't any "rule" that
say that one must specify the type of thing to which that term applies.
On the other hand, I think that it is considered a Bad Thing in RDF to
apply properties to a resource having an unspecified type. It's not
impossible to do so, but specifying the rdf:type of a resource is one of
the most fundamental things that one does in creating a description of
the resource. This is recognized in the TDWG GUID Applicability
Statement (recommendation 11) which says that objects identified by
GUIDs should be typed using a well-known vocabulary. One "well-known
vocabulary" is the Darwin Core Type Vocabulary
(http://rs.tdwg.org/dwc/terms/type-vocabulary/index.htm) There isn't
any formal relationship between the Darwin Core classes in the dwc:
(http://rs.tdwg.org/dwc/terms/) namespace and the types in the dwctype:
(http://rs.tdwg.org/dwc/dwctype/) namespace. We could use the dwctypes
to describe resources that we want to say are instances of dwc: classes
(and meet the GUID guidelines), but that would raise problems that I
will get into later. The point is that as Darwin Core is currently set
up, there isn't a formal relationship between the dwc: classes that are
used to group the terms and the dwctype: types that could be used to
rdf:type them. As it is described, the dwctype vocabulary is simply
stated to be used as values for basisOfRecord and as I pointed out in
the previous post, basisOfRecord only really works when Occurrences are
limited to having a single token.
In RDF, the relationship between classes and types is different from the
way it currently stands in Darwin Core. RDF classes and types are tied
together by definition
(http://www.w3.org/TR/2004/REC-rdf-schema-20040210/#ch_type) If you
assert that a resource has an rdf:type of X, you are simultaneously
asserting that the resource is an instance of class X. The relationship
between a class in RDF and the declaration of rdf:type is so entwined
that naming a XML container element by the class of the resource is an
instance is identical to an explicit declaration of type. The following
two examples produce exactly the same result if you paste them into an
RDF validator like http://www.w3.org/RDF/Validator/ :
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<rdf:Description
rdf:about="http://bioimages.vanderbilt.edu/baskauf/10692#occ">
<rdf:type rdf:resource="http://rs.tdwg.org/dwc/terms/Occurrence"/>
</rdf:Description>
</rdf:RDF>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dwc="http://rs.tdwg.org/dwc/terms/">
<dwc:Occurrence
rdf:about="http://bioimages.vanderbilt.edu/baskauf/10692#occ">
</dwc:Occurrence>
</rdf:RDF>
Even though there is no explicit declaration of rdf:type in the text of
the second example (i.e. the dwc:Occurrence container element is empty),
the validator treats the code as if a type property were stated
explicitly - you can see that the resulting triple and graph created by
the validator shows the RDF as having made an explicit declaration of
rdf:type=dwc:Occurrence.
So my point is that to enable people to follow the TDWG GUID
recommendations and provide RDF that tells people the type of the
resource, TDWG bears a responsibility to provide GUID users with terms
that are suitable for use as an rdf:type property for every class of
resource that we can reasonably be expected to want to assign a GUID.
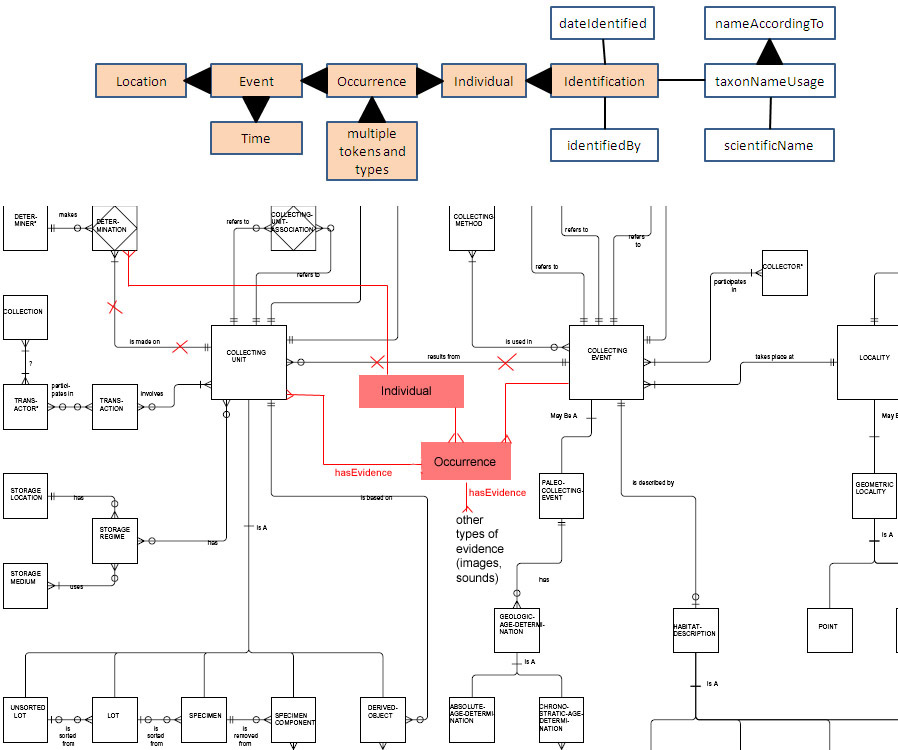
In my book, that's every box shown on the summary diagram
http://bioimages.vanderbilt.edu/pages/full-model.jpg except for tokens
(and excluding Time if we agree that we will always denormalize it out
of existence as a class). I exclude token as a group because they are
not a single class of resource. Any type of resource that provides
evidence that an Occurrence happened can be a token. In some cases
(such as images and sounds) those types are already defined in Dublin
Core. Darwin Core would only need to define types for things that
aren't defined elsewhere, such as the Collecting Units in the ASC model
(but this is the topic of the third installment).
One way to do this (and the way that I favor) is to make sure that there
is a Darwin Core class for every category of resource for which one
would reasonably expect to assign a GUID. Referring to the full model
diagram, the only categories that don't have classes at the moment are
Individual (which I have proposed to add), Time (which may or may not be
necessary), and Collecting Unit (again, more on this in the final
installment). The first category could be created by voting to accept
my proposal about the class Individual. The last would require a new
recommendation, but I think that Rich has pretty much suggested that
this should happen when he says that there are a lot of terms in the
Occurrence category that don't belong there (i.e. they belong with
Collecting Units). So it would make sense from the point of view of a
more logical organization of terms to do this anyway. As Bob has
pointed out, in RDF making a declaration of rdf:type=X is the same thing
as declaring that class X exists. So why not make the rdf:types BE the
Darwin Core classes so we will be declaring something that actually does
already exist instead of conjuring up virtual classes from types that we
make up? There have been some people who have questioned my proposal
for adding Individual as a DwC class on the basis that it is not clear
that anybody "needs" it. What I am stating here is that anybody who
plans to write RDF following recommendations based on a fully normalized
Darwin Core RDF model (which should be EVERYONE who writes RDF using
Darwin Core!) "needs" all of the classes that connect resources they
plan to describe. That means that anybody who plans to connect
Occurrence metadata to Identifications should be doing it in their RDF
through named instances of the dwc:Individual class.
Another alternative would be to fix the dwctype vocabulary, but that
would be messier. The dwctype vocabulary is designated as the
controlled vocabulary for basisOfRecord, so it is a bit dangerous to
mess with it without breaking basisOfRecord. The other problem as was
noted earlier on the list is that currently certain types in the DwC
type vocabulary are declared as subClasses of other types, and that
these declarations will cause unintentional assertions that don't make
sense in the context of the general model that we've been discussing
(namely that every PhysicalSpecimen is an Occurrence which is also an
Event). It seems to me that there is more "fixing" required here than
is worth the effort given that we can just use the classes as the
rdf:types as I described in the previous paragraph.
The final alternative would be to make the TDWG Ontology functional and
use it to type resources. Although there has been some recent
discussion on the list about working on the Ontology, at the present
moment there isn't a clear plan or timeline to finish it. Telling
people to wait for something that may never happen is not an acceptable
alternative to me. I think it is clear that there are multiple people
and institutions that are either ready to write RDF in support of GUIDs
or are already doing it now. Six months is about the longest timeframe
that I think is reasonable for coming up with a solution to the typing
problem discussed above and to have some kind of basic guidelines for
the structuring of RDF. A general model based on the existing Darwin
Core classes is the only path forward that I can see as feasible in that
time frame and a general model could always be build into a more
sophisticated model (i.e. the Ontology) at liesure if anyone cared to
take the time. If TDWG doesn't get its act together on a six-month to
one year time scale, people will simply give up and write Darwin
Core-based RDF without any TDWG guidelines. It has been suggested that
a Task Group be formed to draft a DwC RDF Guide. I would be very keen
to see that happen and would be willing to be involved in the process,
but I'm not interested in it if the process doesn't start out with some
version the consensus model we've discussed here and with some quick
decision from the TAG about how to handle the rdf:typing problem.
Without those two things, there would just be endless unproductive
debate about how to go about building the model from scratch and I've
got better things to do than that.
I will end this with one final comment about the proposed Individual
class in this context. I have stated clearly in several earlier posts
that I don't think that the Individual class really has many properties
and that it functions primarily as a named node to facilitate
one-to-many relationships with other classes. This may strike some
people as odd, given that the primary purpose of classes in the existing
Darwin Core seems to be to group similar terms that can act as
properties for the class. What became apparent to me when I was
creating the diagrams for the first post was that if the Time terms are
pulled out of the Event class (as they probably should be in a fully
normalized model) and the "Collecting Unit" terms are pulled out of the
Occurrence class (as I think must happen if we separate tokens from
Occurrences), there are also very few property terms left in the Event
and Occurrence classes. Most of the terms that remain are
"housekeeping) ones used for remarks, or to make note of the person who
documented the instance and when. Most of the terms that actually
describe measurable properties are found in the peripheral classes like
Location, Time, and Collecting Unit. Just as in the case of the
proposed Individual class, the Event and Occurrence classes are
primarily named nodes that connect other classes. The only reason they
have very many terms at the present is because we have some of the terms
in the "wrong" place for a fully normalized model. I think that it is
also no coincidence that these three classes (Event, Occurrence, and
Individual) are also the three that we have had the most trouble
defining. I think that's precisely because they have very few
properites of their own. They do roughly correspond to things for which
we have conceptual images, which is why we are able to come up with
meaningful names for them. But as I have argued, it is better to define
them according to what we want them to DO rather than by our mental
image of them. And that is a lead-in to the third and final post.
--
Steven J. Baskauf, Ph.D., Senior Lecturer
Vanderbilt University Dept. of Biological Sciences
postal mail address:
VU Station B 351634
Nashville, TN 37235-1634, U.S.A.
delivery address:
2125 Stevenson Center
1161 21st Ave., S.
Nashville, TN 37235
office: 2128 Stevenson Center
phone: (615) 343-4582, fax: (615) 343-6707
http://bioimages.vanderbilt.edu
1
0
Background for the Individual class proposal. 1. Denormalization of models and correspondence to the ASC model
by Steve Baskauf 13 Nov '10
by Steve Baskauf 13 Nov '10
13 Nov '10
This is part 1 of three messages that attempt to summarize the issues
that we have been discussing over the last month and to suggest a
solution and a way forward. If you zone out when you get emails longer
than three lines, please erase the messages and go on with your life.
Unfortunately this is a complicated topic and I'm trying to lay out the
issues in the simplest and most straightforward way that I can. The
first email (this one) describes how a fully normalized model of Darwin
Core can arise from modifying the ASC model to meet articulated needs of
the Darwin Core constituency. The second email will describe why we
need to come to a consensus on this and the criteria that I think should
be considered before a decision is reached. The third email discusses
the issue that Rich has raised as to whether the proposed Individual
class should have a rather narrow scope (as I have advocated) or if it
should be broadened to include other functions. I have separated this
material into three emails because they are really separate but related
issues and may each spawn threads relating to the particular issue.
----------------------------------------------------------------------
To try to get a better understanding of the issues we have been
discussing, I went back to the Association of Systematics Collections
(ASC) information that Stan posted at
http://wiki.tdwg.org/twiki/bin/view/TAG/HistoricalDocuments - in
particular, the chart
http://wiki.tdwg.org/twiki/bin/viewfile/TAG/HistoricalDocuments?rev=1;filen…
I have cut out a section of that chart that will fit on one screen and
have created several images that have various models involving Darwin
Core classes pasted at the top. Each subsequent Darwin Core class model
is more normalized than the previous one. Below each model I show how
that denormalization maps to the ASC model.
The first diagram is the ASC model itself
http://bioimages.vanderbilt.edu/pages/asc-model.jpg
There are several differences in names between ASC and DwC.
dwc:Location corresponds to Locality in ASC, dwc:Event corresponds to
Collecting Event in ASC, dwc:Identification corresponds to Determination
in ASC, and Collecting Unit in ASC corresponds to a subset of what I
have been calling the "token" (evidence), that is limited to organisms,
their pieces, and their conglomerations. One may quibble about exact
correspondence, but I think that fundamentally those things are
congruent. In the ASC model, the lines with crow's feet correspond to
one-to-many relationships, with the foot at the "many" end. In my
diagram a triangle does the same thing with the point of the triangle
representing the "one" end. As you can see, the subset of the ASC model
shown here can summarized in simplified form using DwC classes
(excluding for the time being the parts of the model that fall into the
DwC Taxon class). The ASC model reflects the "museum" perspective: in
many or most cases the whole organism is collected, or if only part of
the organism is collected (e.g. tree branch) the organism is rarely
re-visited for additional collections. So this model is denormalized
(flattened) to the extent that it doesn't allow for multiple types of
tokens per organism and resampling of the organism over time.
The second diagram represents Darwin Core at the time it became a
standard in 2009.
http://bioimages.vanderbilt.edu/pages/darwin-core-model.jpg
The difference from the previous diagram is the creation of the
Occurrence class. This class recognizes the needs of the observation
community because it allows one to connect Events to Determinations
directly without forcing them to be associated with a physical object
(token). This modification was beneficial because terms describing the
act of documenting the presence of a taxon during an Event are shared
between observations and specimen collection. This model presupposes
that there is no more than one token per Occurrence. dwc:basisOfRecord
is used to describe the nature of that one token. Terms for handling
tokens other than specimens are not well developed.
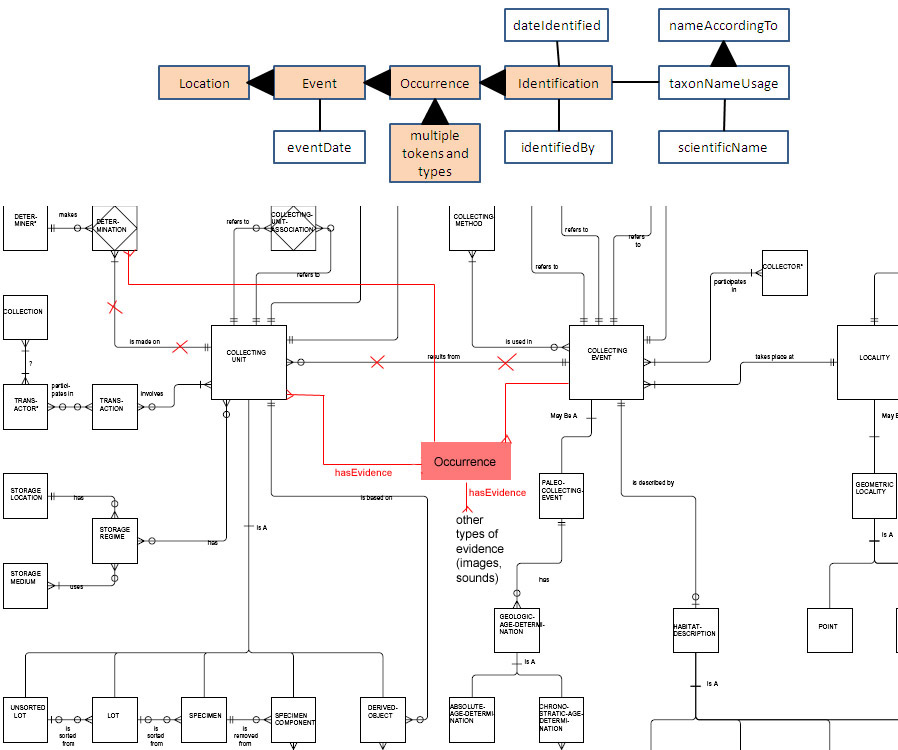
The third diagram is a slight modification of the second and is what
I've been calling the "explicit token" model:
http://bioimages.vanderbilt.edu/pages/dwc-explicit-token-model.jpg
The only difference between it and the previous model is that there is
now recognition that the token is a separate thing from the Occurrence.
Types of tokens other than specimens (such as images and sounds) are
recognized explicitly as means of documenting Occurrences. The lines
connecting Occurrence to tokens have "crow's feet" on the token side,
allowing that there may be one to many tokens that act as evidence for a
single Occurrence. When I complain that basisOfRecord "doesn't work",
it is with this model in mind. In this model, there is not one single
"basis" (token) for a record - under this model there would need to be
the possibility to have multiple basisOfRecord values for an Occurrence,
which I don't really think is supported currently in DwC.
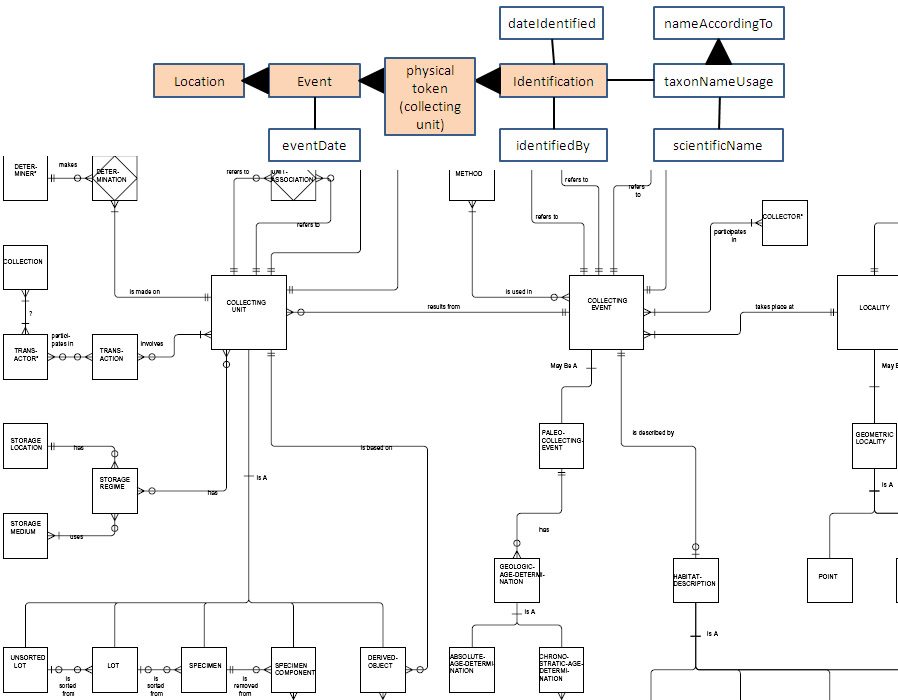
The fourth diagram, which I call the "full model" adds one more
component to the explicit token model:
http://bioimages.vanderbilt.edu/pages/full-model.jpg
This model is what I consider to be the fully normalized version of
Darwin Core (excluding the Taxon parts). This model introduces the
Individual class exactly as I have defined it in my proposed term
addition: as a node that connects Occurrences to Identifications (a.k.a.
Determinations). This is not really an addition to the existing Darwin
Core standard because the term individualID already exists in the
Occurrence class. My proposal simply gives a name to the thing that is
the object of individualID - in fact my original justification for the
term addition says exactly that. The fundamental purpose that
Individual serves is to accommodate the "crow's foot" on the Occurrence
side of the line that connects Individual to Occurrence, i.e. to allow
re-sampling over time and space. That is all. The line going to
Identification/Determination has to be connected somewhere and it makes
sense to connect it to Individual rather than Occurrence since the
resampled entity is not going to change its identity from one sampling
to another.
I have done one more thing in this model to make it more denormalized.
It's a spin-off from Paul Murray's post
http://lists.tdwg.org/pipermail/tdwg-content/2010-October/001771.html
which got me to thinking that if we were to treat time in the same way
we are treating Locations and other entities a fully normalized model
would have a class for Time since time can have varying degrees of
specificity (just like Location and Taxon) and there is a one-to-many
relationship between Time and Event (i.e. there can be many Events going
on at different Locations at a given Time, just like there can be many
Events at different Times at a given Location). We almost always
denormalize the Time class out of our models because in most cases it
can be represented as a single ISO 8601 string. But as Paul points out,
Time can be a complicated thing that one might want to model in a more
sophisticated way than a single string. I'm not suggesting that we
should do this in Darwin Core if nobody needs it, but the point is that
it COULD be done. There probably already is a class for Time defined by
somebody else (does anyone know about this?).
In summary, the fully normalized model that I have presented seems to be
consistent with almost all of the discussion that has taken place on the
list recently. Although the ASC model is "more normalized" than this in
some parts, I haven't heard many of the participants in the discussion
advocating for a general Darwin Core model that is more complex than
what I've presented in the last link. Obviously, individuals (humans)
could add many more classes of things in their own personal models, but
I think the classes in this last model can acommodate nearly all of the
resources people have said that they want to describe using Darwin Core.
End of part 1
--
Steven J. Baskauf, Ph.D., Senior Lecturer
Vanderbilt University Dept. of Biological Sciences
postal mail address:
VU Station B 351634
Nashville, TN 37235-1634, U.S.A.
delivery address:
2125 Stevenson Center
1161 21st Ave., S.
Nashville, TN 37235
office: 2128 Stevenson Center
phone: (615) 343-4582, fax: (615) 343-6707
http://bioimages.vanderbilt.edu
1
0

TaxonConcept Ontology, Test Data Set, SPARQL Endpoint, HTML and RDF representations
by Peter DeVries 11 Nov '10
by Peter DeVries 11 Nov '10
11 Nov '10
I have cleaned up my ontology* at :
http://lod.taxonconcept.org/ontology/txn.owl
<http://lod.taxonconcept.org/ontology/txn.owl>It validates here:
http://owl.cs.manchester.ac.uk/validator/
Here is a small sample of species concepts, occurrences and related data in
one gzipped .rdf
http://lod.taxonconcept.org/txn_base.rdf.gz
It includes these examples: http://lod.taxonconcept.org/examples.html
This small file should allow people to test inferencing etc.
I expect and would encourage people to try it to see if they can find
something wrong, or some utility that they would like.
I have a sparql endpoint that is described here:
http://www.taxonconcept.org/sparql-endpoint/
The data set should also be available on the LOD Cloud Endpoint
http://lod.openlinksw.com/sparql
http://lod.openlinksw.com/isparql/
* This is live most of the time except when I am updating the server or
data.
The HTML and RDF representations have changed since my last update.
Here is are two examples:
http://lod.taxonconcept.org/ses/iuCXz.html
http://lod.taxonconcept.org/ses/iuCXz.rdf
<http://lod.taxonconcept.org/ses/iuCXz.rdf>
http://lod.taxonconcept.org/ses/dwAmr.html
<http://lod.taxonconcept.org/ses/dwAmr.html>
http://lod.taxonconcept.org/ses/dwAmr.rdf
<http://lod.taxonconcept.org/ses/dwAmr.rdf>* Once I have this worked out I
have no problem with TDWG/GBIF/EoL taking this over.
I just need a live namespace in which changes can be made quickly.
Respectfully,
- Pete
---------------------------------------------------------------
Pete DeVries
Department of Entomology
University of Wisconsin - Madison
445 Russell Laboratories
1630 Linden Drive
Madison, WI 53706
TaxonConcept Knowledge Base <http://www.taxonconcept.org/> / GeoSpecies
Knowledge Base <http://lod.geospecies.org/>
About the GeoSpecies Knowledge Base <http://about.geospecies.org/>
------------------------------------------------------------
1
0

"Alpha and Beta discuss the lack of a semantically rich version of the
Darwin Core."
you are a bad man Bob Morris... :)
http://www.xtranormal.com/watch/7632561/
--
_________________
Jim Croft ~ jim.croft(a)gmail.com ~ +61-2-62509499 ~
http://www.google.com/profiles/jim.croft
'A civilized society is one which tolerates eccentricity to the point
of doubtful sanity.'
- Robert Frost, poet (1874-1963)
2
1
Request for vote on proposals to add Individual as a Darwin Core class and to add the term individualRemarks as a term within that class
by Steve Baskauf 11 Nov '10
by Steve Baskauf 11 Nov '10
11 Nov '10
I am pleased with the significant and thoughtful discussion that has
taken place on the tdwg-content email list regarding the relationships
among Occurrences, Individuals, and other entities that are a part of
the community's thinking about biodiversity metadata and the way that
those metadata are structured. It appears from the discussion that
there is widespread acceptance of the idea that Individual as a concept
has a place in the structuring of biodiversity metadata and that there
is some consensus of what "Individual" means (i.e. an entity ranging
from actual biological individuals to small coherent populations that
can reliably be asserted to represent a single taxon). Whether that
acceptance and consensus constitutes a compelling need for adding two
new terms (the class dwc:Individual and dwc:individualRemarks) to the
Darwin Core standard or not is the point of a TAG "vote". Given the
discussion that has occurred, it seems to me that there are two reasons
why there is an actual need for those terms. One reason is that if
members of the Darwin Core constituency intend to structure their
metadata in a fully normalized manner that includes grouping Occurrences
by Individuals (and it appears that there are at least several who
intend to do this), the term dwc:individualRemarks is needed to provide
a means indicate the nature of the individual (i.e. is it a biological
individual, clonal individuals, a small population, etc.?) and the class
dwc:Individual is needed as the category within which to put
individualRemarks so as to indicate that individualRemarks is a property
of Individuals. The second reason for explicitly recognizing
Individual as a class is that it would place a term representing the
concept of "Individual" within a "well-known vocabulary". I feel that
would be critical for facilitating the ultimate development of a
recommendation for the representation of Darwin Core as RDF.
At this point, it is not clear to me that there are any other existing
DwC terms that should be moved to a new Individual class. Originally, I
suggested that individualCount should be placed in that class, but I no
longer think so. Counting the number of individuals is really something
that happens when an Occurrence takes place and a small cohesive group
of a single taxon (e.g. wolf pack or plant population) could have an
individualCount that changes over time. As was discussed earlier in on
the email list, the xxxxxxID terms probably really belong in the
Record-level terms category rather than being listed within particular
classes. So I don't believe that dwc:individualID should be in the
proposed class either. As I detailed in my Biodiversity Informatics
paper, an Individual is really an entity that serves primarily as a node
that allows the grouping of other resources (namely Occurrences and
Identifications). As such, it really has few (or no) properties that
can be known outside of Occurrences.
Thus I would like to "call the question" on the issue of the proposal.
I would suggest that the issue of adding the class dwc:Individual and
the term dwc:individualRemarks within it be addressed in a single vote,
since there little point in having one term without the other. I would
also hope that those on the TAG who choose to vote would review the list
discussion carefully first. Given that the question of "what exactly is
an Individual?" came up a few times after that question was clearly
answered in the thread is an indication that some people entered the
thread later on without the benefit of having read some of the earlier
posts.
Steve
--
Steven J. Baskauf, Ph.D., Senior Lecturer
Vanderbilt University Dept. of Biological Sciences
postal mail address:
VU Station B 351634
Nashville, TN 37235-1634, U.S.A.
delivery address:
2125 Stevenson Center
1161 21st Ave., S.
Nashville, TN 37235
office: 2128 Stevenson Center
phone: (615) 343-4582, fax: (615) 343-6707
http://bioimages.vanderbilt.edu
10
20

Steve is using Species as ranks in his definition and I think this is the wrong approach. Let's make all this rank agnostic please! Use the word taxon! What if I have a group of organisms that represents a polyphyletic species and I want to name a lineage (group of organisms) within this traditionally recognized species that I am not recognizing as species per se (as in rank of species). In other words, Identifications and ranks are two different things, so let's abandon ranks for a more objective discussion on taxa. Individuals are definitively not species.
Nico (the other one)
>
> On Wed, Nov 3, 2010 at 7:24 AM, Steve Baskauf <steve.baskauf(a)vanderbilt.edu> wrote:
>
> John,
> I'm not sure that I agree with your analysis that the definition prevents the possibility of making an Identification at a rank less specific than a species. My revised definition says that the Individual should only include groups of organisms that are reliably known to be of a single species - it doesn't say that we need to know what that species is (i.e. an identification to genus or family can be made with the hope that someone down the line would be able to refine the identification to species). Clarification on this point could be added to the comment or the Google Code page, but I don't think there is a problem with the definition per se. However, if there is a consensus that the definition is too restrictive, I would not object to changing the wording of the definition from "species (or lower taxonomic rank if it exists)" to "taxon" if there were clarification added to the comments or Google Code page that Individual was not intended to include aggregations of mult
>
> iple species.
>
> I agree that there is a need for a term that represents "collections", "bags", "aggregations", or whatever you want to call an aggregation that includes multiple species. But I have never intended that Individual should be that term. If we expand Individual to include aggregates, then it becomes unusable for its original intended purpose. I would prefer for someone to propose a different term for aggregates of individuals instead of adding that function to Individual. Then define the relationship of this new thing to Individual as a one:many relationship (one aggregation:many Individuals).
>
> Steve
>
>
> John Wieczorek wrote:
> Most of you probably do not receive postings from the Google Code site for Darwin Core. Steve B. updated the proposal for the new term Individual, and then commentary ensued on the Issue tracker. Since there remains an unresolved issue, I'm bringing the discussion back here by adding the commentary stream below. The unresolved issue is Steve's amendment is the restriction in the definition to "a single species (or lower taxonomic rank if it exists)."
>
>
>
> Rich argues that we should not obviate the capability of applying an Identification to an aggregate (e.g., fossil), where the aggregate consists of multiple taxa.
>
> Steve argues that Identifications should be applied only to aggregates of a single taxon.
>
>
>
>
> Steve, aside from the aggregate issue (which should be solved satisfactorily), your suggestion is too restrictive, because it would obviate the possibility of making an Identification (even for a single organism) to any rank less specific than a species. That is a loss of capability, and therefore unreasonable.
>
>
>
>
>
> Comment 7 <http://code.google.com/p/darwincore/issues/detail?id=69&colspec=ID%20Type%2…> by baskaufs <http://code.google.com/u/baskaufs/> , Today (8 hours ago)
> As a result of the discussion that has taken place on the tdwg-content email list during 2010 October and November, I am updating the term recommendation for Individual as follows:
>
> Definition: The category of information pertaining to an individual organism or
> a group of individual organisms that can reliably be known to represent a single species (or lower taxonomic rank if it exists).
>
> Comment: Instances of this class can serve the purpose of connecting one or more instances of the Darwin Core class Occurrence to one or more instances of the Darwin Core class Identification.
>
> Refines: N/A
>
> Please note that as a precautionary measure, I have removed the statement that Individual refines http://purl.org/dc/dcmitype/PhysicalObject because the definition of PhysicalObject specifically mentions that the object is inanimate. I am not currently aware of any well-known term that defines living things.
>
> Steve Baskauf
>
>
>
>
> Delete comment <http://code.google.com/p/darwincore/issues/detail?id=69&colspec=ID%20Type%2…>
>
> Comment 8 <http://code.google.com/p/darwincore/issues/detail?id=69&colspec=ID%20Type%2…> by deepreef(a)hawaii.rr.com <http://code.google.com/u/deepreef@hawaii.rr.com/> , Today (8 hours ago)
> I think the definition should be "...represent a single taxon". We shouldn't restrict it to members of the same species (or lower), because then we technically can't include things that may represent more than one species, yet would best be treated within the scope of an Individual.
>
> Also, I'm slightly partial to the term "Organism" for this class, rather than "Individual", because it's more clearly tied to the biology domain, and less likely to collide with the word "Individual" in other domains. I know such collision is not a technical problem, but it might lead to some confusion.
>
>
>
> Delete comment <http://code.google.com/p/darwincore/issues/detail?id=69&colspec=ID%20Type%2…>
>
> Comment 9 <http://code.google.com/p/darwincore/issues/detail?id=69&colspec=ID%20Type%2…> by baskaufs <http://code.google.com/u/baskaufs/> , Today (8 hours ago)
> Well, the reason that I defined it to be members of the same species is to ensure that the term Individual can serve the primary function that I perceived was needed: to make the connection from occurrences to identifications. When I said one or more identifications, I meant one or more opinions about what that single species (or lower) was, not that there could be multiple identifications of several different species that happened to be in the same "bag" such as the contents of a pitfall trap containing multiple species, an image that contained several species, or a specimen that contained parasites of a different species. I think that there is a need for a term for this other kind of thing, (a heterogeneous "lot", "batch", or something), but I think that including this in definition of Individual defeats the purpose for which I proposed it. If there were several different species in the "Individual", then
> one would have to specify which identification went with which biological individual within the "lot", which would result in actually breaking down the "lot" into single species "Individuals" anyway.
>
>
7
33

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Collections contain things that do not map nicely to a single taxon name of
any (or no) rank. It's not clear to me if this proposal will support those
kinds of data or not. A few examples:
Uncertainty: http://arctos.database.museum/guid/KWP:Ento:1703
Composite specimens: http://arctos.database.museum/guid/UAM:Herb:12718
Hybrids: http://arctos.database.museum/guid/UAM:Mamm:3517
Things that aren't taxonomy at all:
http://arctos.database.museum/guid/UAM:ES:3405
-D
On Wed, Nov 3, 2010 at 10:07 PM, Peter DeVries <pete.devries(a)gmail.com>wrote:
>
> What I would recommend is that you treat a specimen that is identified to
> an order (Perciformes) with something like the following.
>
> Species => Order Perciformes species undetermined.
>
> The individual is still an instance of a species, however that species has
> yet to be determined.
>
> What would work best is to have some standard way of writing the green
> string above.
>
> This would allow the occurrences that are of individuals identified only to
> the Order Perciformes, to be interpreted as a species that falls somewhere
> within the Order Perciformes.
>
> - Pete
>
>
> ---------------------------------------------------------------
> Pete DeVries
> Department of Entomology
> University of Wisconsin - Madison
> 445 Russell Laboratories
> 1630 Linden Drive
> Madison, WI 53706
> TaxonConcept Knowledge Base <http://www.taxonconcept.org/> / GeoSpecies
> Knowledge Base <http://lod.geospecies.org/>
> About the GeoSpecies Knowledge Base <http://about.geospecies.org/>
> ------------------------------------------------------------
>
> _______________________________________________
> tdwg-content mailing list
> tdwg-content(a)lists.tdwg.org
> http://lists.tdwg.org/mailman/listinfo/tdwg-content
>
>
4
7
What is an Occurrence? [followup to "Wrong" RDF and What I learned... threads]
by Steve Baskauf 04 Nov '10
by Steve Baskauf 04 Nov '10
04 Nov '10
After the flurry of emails recently, I had an opportunity to carefully
read all the way through the threads again, followed by enforced "think
time" during my long commute. I was actually pretty cheerful after that
because I think that in essence, most of the conversation about what
constitutes an Occurrence really boils down to the same thing. So I
have sat down and tried to summarize what seems to me to be a consensus
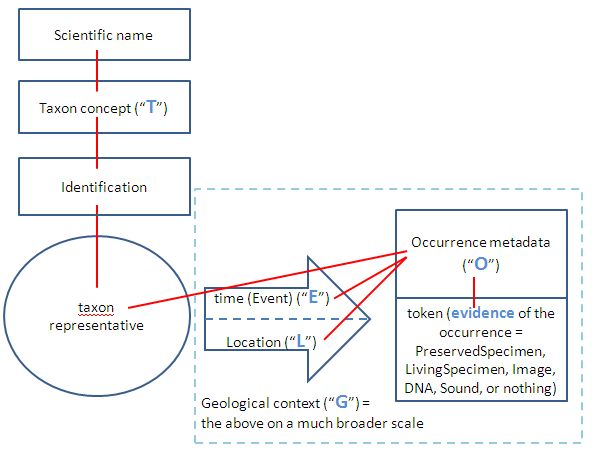
about Occurrences. To follow my points, please refer to the diagram at:
http://bioimages.vanderbilt.edu/pages/occurrence-diagram.gif
Consensus on relationships
1. The fundamental definition of an Occurrence involves evidence that a
representative of a taxon occurred at a place and time.
Note 1.A: For clarity, I have modified John's statement in his last
email by replacing "taxon" with "representative of a taxon". I'm
considering a taxon to be an abstract concept that is applied to
individuals or groups of organisms.
Note 1.B. This definition is far more useful than the official
definition of the class Occurrence "The category of information
pertaining to evidence of an occurrence..." which is essentially circular.
Note 1.C: This statement is extremely broad because the evidence could
be of many sorts, the representative could range from a single
individual to all organisms on the earth, the taxon could be anyone's
definition at any taxonomic level, the place could range from a GPS
point with uncertainty of less than 10 meters to the entire planet
earth, and the time could range from a shutter click of less than one
second to 3.4 billion years.
2. The diagram is an attempt to summarize in pictorial form statements
and relationships that have been described in the thread. The taxon
representative is recorded as existing at a particular time and place
(the arrow) and the result is an Occurrence record. That Occurrence
record exists as metadata which may be associated with a token that can
be used to voucher the fact that the taxon representative existed. That
token may be the organism itself (or a living part of it as in a twig
for grafting), all or part of the organism in preserved form, an
electronic representation such as an image or sound recording, and other
kinds of things like tissue or DNA samples. There may also be no token
at all, in which case we call the Occurrence record an observation.
Based on direct observation of the taxon representative, examination of
one or more tokens, or both, some determiner asserts that a taxon
concept applies to the taxon representative and as a result a scientific
name can be used to "identify" the taxon representative. (There may be
a lot of other complicated stuff above the Identification box, but that
will have to be filled in by the taxonomists.)
Note 2.A: I have mapped onto this diagram the letters that John used in
his last email to refer to entities that are involved in an Occurrence
(T, E, L, O, and G). I will beg the forgiveness of fossil people
because I don't really know how the geological context fits in. I'm
assuming that it is a way of asserting time and location on a much
broader scale than we do for extant organisms.
Note 2.B: I have put a dotted line around the part of the diagram that I
think includes all the things that people might consider part of the
Occurrence itself. I have left out "T" and the other parts related to
identification because it seems to me that you can have an occurrence
that you document which does not yet (and perhaps never will) have an
identification. The Occurrence still asserts that a taxon
representative existed at a time and place; we just don't yet know what
the taxon is.
3. The red lines indicate the relationships that connect the various
entities (I'm going to go ahead and call them resources). Consistent
with popular opinion, the Occurrence record is the center of the
universe and most things are connected to it.
Note 3.A: I am sticking to my guns and refuse to connect the
Identification directly to the Occurrence. It is the taxon
representative that is being identified, not the occurrence. One can
assert another sort of relationship between the identification and the
occurrence if one wants to say that one consulted the occurrence
metadata and token in order to decide about the identification, but it
is not correct to say that the Identification identifies either the
Occurrence metadata or the token (as Rich pointed out).
OK, so that's step one - defining what is related to what. If anyone
disagrees with these relationships, please clarify or create your own
diagram.
Complicating circumstances/caveats
1. It is noted and recognized that some users will not care to include
all of these relationships in their models. In the interest of
simplification or "flattening" the relationships, they may wish to
collapse some parts of this diagram (e.g. incorporate time and location
metadata within the Occurrence metadata rather than considering them
separate resources, applying scientific names directly to the taxon
representatives without defining a taxon concept or recording the
determination metadata, connecting identifications directly to the
occurrence, etc.). This doesn't mean that the relationships don't
exist, it just means that some users don't care about them.
2. It is recognized that different users will be interested in or able
to specify the various resources to differing degrees of precision.
Examples: A photographer might record times to the nearest second, a
collector may only be interested in noting the date on which a specimen
was collected. A location may be specified to the precision of a GPS
reading or be defined as some geographic or political subdivision. The
taxon representative may be an individual organism, a flock or clump, or
some larger aggregation of taxon representatives.
That's step two. If I've missed any complications, please point them out.
My opinions about the implications of this diagram
1. The circle I've labeled as "taxon representative" is the resource
type that I'm proposing to be represented by the class Individual. You
will note that in both the definition of dwc:individualID ("An
identifier for an individual or named group of individual organisms...")
and the proposed class definition ("The category of information
pertaining to an individual or named group of individual organisms
represented in an Occurrence"), groups of individual organisms are
included. Thus John's example of a fossil having myriad individuals, or
Richard's examples of thousands of plankton, a large school of fish,
herd of wildebeest, flock of
birds, could all be categorized as "Individual" under this definition if
there is a reasonable expectation that all of the individuals in the
group are members of the same taxon. Perhaps there is a better name for
this resource, but since dwc:individualID was already extant, I chose
Individual as the class name for consistency with the pattern
established with other classes and their associated xxxxID terms.
2. Although in note 1.C. I have given the ranges of the various
resources to their logical extreme (as was done previously in the
thread), I think that as a practical matter we can adopt guidelines to
set reasonable values for the "normal" ranges of the resources. One
such guideline might be that we suggest a range that can accommodate
about 95% of the user needs within the community (this came from Rich's
comment about satisfying 95% of the user need with an establishmentMeans
controlled vocuabulary). For example, it was suggested that the range
for the location of an Occurrence could span the entire planet Earth.
True enough, but virtually nobody would find such a span useful. 95% of
users would probably find a range between a GPS reading with 10 meter
precision and the extent of a county or province useful for recording
the location of an Occurrence. I can suggest similar "useful" ranges:
one second to one day for an event time (excluding fossils), one
individual organism to the number of organisms that would fit within a
50 meter radius for an "individual", and taxon identified to family for
plants and maybe mammals, genus for birds, and order for insects. So
framing the definition of an Occurrence in these terms it would be
something like: "An occurrence involves evidence (consisting of a
physical token, electronic record, or personal observation) that a
representative (ranging from a single individual to the number that
would fit on a football field) of a taxon (hopefully identified to some
lower taxonomic level) occurred at a place (determined to a precision
between that of a GPS reading and the size of a county/province) and
time (spanning one second to one day)." A few people might object to
this level of restrictiveness, but I would guess that it would make 95%
of us happy.
3. With the exception of the "missing" class Individual, every resource
type on this diagram except for the "token" and Scientific name has a
Darwin Core class. Every resource type on the diagram except for "token"
has a dwc:xxxxID term that can be used to refer to a GUID for the
resource. The implication of this is that any resource on this diagram
except for the token and taxon representative (i.e. Individual) is ready
to be represented in RDF by Darwin Core terms in the sense that the
relationships (red lines) can be represented by the xxxxID terms and
that the resources can be rdfs:type'd using Darwin Core classes.
(Lacking a class for the scientific name doesn't seem like a big deal to
me since the scientific name can be a string literal - but then I'm not
a taxonomist.)
4. OK, I've avoided it as long as I can, so I'm going to confess now to
the RDF-phobes. The red lines and shapes are something pretty close to
an RDF graph. What that means is that if the community can agree that
this diagram correctly represents the relationships among the kinds of
biodiversity resources that we care about, then the matter of providing
guidelines on how to represent Darwin Core in RDF suddenly gets a lot
simpler. Just convert the "picture" of the RDF graph into XML format
and we have a template. Alright, that's an oversimplification, but I
think it is essentially true because the most difficult part of
achieving a consensus on RDF representations is to decide how we connect
the resource types, not on the literals that we hang onto resources as
properties.
5. While I'm beating the RDF drum again, the importance of my opinion
number 2 can be extended into the GUID adoption process. In my comments
to Kevin about the Beginner's Guide to Persistent Identifiers, I think I
commented on the question of how one decides whether a GUID needs to be
assigned to something or not. I believe that the answer to that
question boils down to this: we need a GUID for any resource that will
be referenced by more than one other resource. Do we need to be able to
assign a GUID to Taxon concepts? Yes, because it is likely that many
identifications will want to reference a particular taxon concept. Do
we need to be able to assign a GUID to an Event? Maybe or maybe not.
If every occurrence has its own separate time recorded, then no GUID is
needed because the time is just a part of every separate occurrence
record. If the event is defined to be a time range that represents a
collecting trip, then there may be many Occurrences that are associated
with that trip and all of them could reference the GUID for that event
rather than repeating the event information for every Occurrence. The
point here is that every shape (class of resources) on this diagram at
least has the POTENTIAL to be a node connecting multiple resources and
therefore should have the capability of being assigned a GUID, having
its own RDF record, and being appropriately typed (presumably by a DwC
class). So this is a final technical argument for why we need to have
the DwC class Individual. Whether or not people ultimately choose to
assign GUIDs to particular resource types or not is their own choice,
but they need to at least be ABLE to if they need that resource to serve
as a node given the structure of their metadata.
We need to clarify how the "token" thing fits in, but I'm stopping there
for now. I would very much appreciate responses indicating that:
A. you agree with the diagram and connections (and consider this
definition and diagram a consensus)
B. you disagree with the diagram (and articulate why)
C. you provide an alternative diagram or explanation of the
relationships among the classes related to Occurrences.
Thanks for you patience with another tome.
Steve
--
Steven J. Baskauf, Ph.D., Senior Lecturer
Vanderbilt University Dept. of Biological Sciences
postal mail address:
VU Station B 351634
Nashville, TN 37235-1634, U.S.A.
delivery address:
2125 Stevenson Center
1161 21st Ave., S.
Nashville, TN 37235
office: 2128 Stevenson Center
phone: (615) 343-4582, fax: (615) 343-6707
http://bioimages.vanderbilt.edu
{kind=link}
16
53
OK, I know that this sounds like a stupid question, but I really want
somebody who was involved in the development and maintenance of the
current DwC standard to tell me how the term dwc:basisOfRecord is
supposed to be used (not what it IS - I've seen the definition at
http://rs.tdwg.org/dwc/terms/index.htm#basisOfRecord)? I would like for
the answer of this question to be separated from the issue of what the
Darwin Core type vocabulary
(http://rs.tdwg.org/dwc/terms/type-vocabulary/index.htm) is for.
I re-read the lengthy thread starting with
http://lists.tdwg.org/pipermail/tdwg-content/2009-October/000301.html
which talked a lot about basisOfRecord and its relationship to other
ways of typing things. I don't want to re-plough that ground again, but
I couldn't find the post that stated what the final decision was. I
remember that there was a decision to NOT create the recordClass term
which was the subject of much discussion.
I guess my confusion at this point is with the inclusion of both
"Occurrence" and "PreservedSpecimen" in the same list. Let's say that I
have a flat database where I include metadata about the Occurrence (such
as dwc:recordedBy) and the specimen (such as dwc:preparations) in the
same line. What is the basisOfRecord for that line? I would guess that
the "basis of the record" was the specimen. But the line in the record
also represents an Occurrence. It seems like there is a lack of clarity
as to whether basisOfRecord is supposed to indicate the type of the
record (which would be an Occurrence record) or whether it's supposed to
indicate the kind of evidence on which the record is based (which would
be PreservedSpecimen). There have been various times where I've seen a
database record that includes basisOfRecord and it seems to be
inconsistently applied.
I can see how the Darwin Core type vocabulary could be useful - it
pretty much lays out useful values that one could give for rdfs:type.
But basisOfRecord as a term is confusing me.
Steve
--
Steven J. Baskauf, Ph.D., Senior Lecturer
Vanderbilt University Dept. of Biological Sciences
postal mail address:
VU Station B 351634
Nashville, TN 37235-1634, U.S.A.
delivery address:
2125 Stevenson Center
1161 21st Ave., S.
Nashville, TN 37235
office: 2128 Stevenson Center
phone: (615) 343-4582, fax: (615) 343-6707
http://bioimages.vanderbilt.edu
4
8
I have been dreading trying to write this post which I have promised (or
threatened depending on if you have enjoyed or been annoyed by the
previous lengthy thread) for some time. I have dreaded it because this
is a complicated subject and not one that is amenable to terse
messages. However, after the previous conversation with Rich et al., I
feel for the first time that I have the questions (not answers!) clearly
in my mind. So rather than starting off rambling about LivingSpecimens
and establishmentMeans as I had planned, I'm going to start by laying
down several principles that have come into clarity in my mind after the
previous conversation and the attempt to map things out in a diagram. I
will apologize in advance for failure to use the correct database or IT
technical terms when I'm in unfamiliar territory. Until there is a
consensus about how we deal with the "tokens" we use to document
Occurrences, I'm not sure that what I have to say about those other
topics will make sense.
PRINCIPLES (derived from earlier discussion)
1. We have a number of kinds of "things" (which I will henceforth refer
to as "resources") that are useful for describing and organizing
metadata that we collect in our attempts to document biodiversity. For
many of these types of resources, we have defined classes to categorize
the terms that can be used to describe the properties of resources that
are instances of that class. Describing the class helps us to
understand the type of resources that constitute instances of that class.
2. A conscious decision was made to avoid formally defining rdfs:domain
for Darwin Core terms. This decision was made to provide flexibility in
the way the terms can be used and to avoid the situation where semantic
clients would draw incorrect or silly conclusions about what kind of
things resources are. However, this decision does not excuse us from
thinking carefully about whether a term can be appropriately applied to
a resource that is a member of some class (e.g. should we say that a
digital photograph has a scientific name?). Placing a term within a
class is a suggestion that the term would appropriately be applied as a
property of an instance of a class.
3. When users want to "flatten" and simplify their databases, they tend
to eliminate one-to-many (1:M) relationships in favor of one-to-one
(1:1) relationships. The result of that is differences like we saw in
http://bioimages.vanderbilt.edu/pages/rich-diagram1.gif (which allows
1:M relationships between Occurrences and Events and between Events and
Locations) and
http://bioimages.vanderbilt.edu/pages/rich-diagram2.gif (which
"atomizes" every Occurrence by considering it to have its own separate
eventTime and Location information).
A. There is nothing intrinsically "right" or "wrong" about either of
these approaches, because they each have their own advantages. The 1:M
approach is more efficient, but results in a more complicated database,
while the 1:1 approach results in a simpler database but may require
repeating some or many term values in the records.
B. The choices that users make in these situations is the cause of much
of the disagreement about whether a certain class should exist or not
since the people taking the 1:1 approach "collapse" the relationship
diagram and eliminate classes they don't need while people who take the
1:M approach need instances of the class to act as nodes to connect
their "many" resources to some other thing.
C. This collapsing of the diagram is also the reason for some
disagreement about whether a term belongs in a certain class or not. In
the example above, 1:1 people would say that eventDate is a property of
an Occurrence, while 1:M people would say that eventDate is a property
of an Event.
D. The choice of users on this issue influences their decision about
whether or not to create resources that are instances of classes and
hence to assign them identifiers. If users take the 1:M approach, they
need identifiers for resources that are acting as connecting nodes so
that they can make reference to that resource in the metadata of the
many things they are connecting to it. If users take the 1:1 approach,
they probably will skip creating explicit resources (and their
corresponding identifiers) for resources of the class that they are
"collapsing" out of the diagram).
4. I would propose that the "right" relationship diagram is not
necessarily one that caters to a certain "right" philosophical point of
view. Rather, the "right" diagram is the one that allows users to
define the relationships that they need for the organization of their
metadata in the simplest manner, and which provides the most clarity
about what resources of various kinds are, and how they are connected.
A. "Right" as I have defined it above depends on how broadly applicable
the relationship diagram is intended to apply. An individual person or
organization with limited interests may have a relationship diagram that
is simpler than the diagram shown at
http://bioimages.vanderbilt.edu/pages/rich-diagram1.gif or might choose
to add classes for other things that are their personal interest. An
organization interested focused on different issues or with broader
interests might opt for many more or different classes that would be
connected to those shown in the diagram.
B. Given what I just said in A, what is "right" for Darwin Core is going
to be defined by the needs of the Darwin Core constituency. At the TDWG
meeting, John Wieczorek made a statement which I will paraphrase as "in
order for a term to make it into Darwin Core, at least two people had to
want it". I'm not sure to what extent he was joking about this, but it
makes the point that one must consider community needs before saying
that a certain part of the "diagram" is necessary. I think that the
reason that Rich and I were so quickly able to come to a consensus on
the organization of the left side of the diagram is because he realized
that there was a significant part of the DwC constituency that needed a
way to group occurrences (i.e. needed Individuals) and I realized that
there was a significant part of the constituency that needed to group
multiple Events at a Locality and multiple Occurrences at an Event. So
in evaluating alternative conceptual systems for organizing resources,
the question has to be asked as to the extent that an alternative allows
broad segments of the DwC constituency to organize their metadata in an
efficient and conceptually sensible way. If one alternative is more
broadly applicable and conceptually clear than another, then that
alternative is better regardless of the philosophical underpinnings of
the argument.
5. The last point is one that has run as an undercurrent through various
TDWG threads but which may not have been explicitly stated in this
particular thread. That is that there should be a separation between
what a resource IS and what we want to use a resource FOR. To use
technical terms, we need to separate the "type" of a resource from its
fitness of use. A digital image IS a digital image. It might be used
FOR documenting that an organism was at a particular location at a
particular time, but it could be used to illustrate a character, as a
part of a visual key, as media for an educational presentation, as art,
and probably many other things that aren't popping into my mind at the
moment. I believe that much of the confusion about "what is an
Occurrence" comes from a failure to make this distinction.
THE ISSUE OF THE TOKEN
Earlier in the thread of "What is an Occurrence", there was a general
consensus that an Occurrence often had a "thing" that was associated
with it that served as evidence that a taxon representative (i.e.
Individual) occurred at a particular Location at a particular time. In
my Biodiversity Informatics paper, I called this thing a
"representation", but I now believe that "token" is a better term and
will use it hereafter. There also seemed to be a consensus that an
observation was simply an Occurrence that did not have an associated
token. (This is with the understanding that observation is being
narrowly defined as a type of Occurrence, with a definable time and
location, as opposed to what I called the "checklist" definition which
indicated that some undefined taxon representative was present in some
defined geographical area at an indefinite time.) In one of my earlier
posts, I pleaded for somebody to tell me whether there was an assumption
that the token was considered a part of the Occurrence or whether it was
a separate thing. I did not get any responses, which I'm construing to
mean that people weren't sure about this. At the present, I now have a
clearer idea of the general principles I outlined above, and also have
the "Rich" diagram for modeling relationships, so I'm going to again
pose this question, but in what I hope is a clearer way. I have re-made
the earlier diagram as Rich suggested, using triangles rather than
arrows. The wide side of the triangle is the "many" side of the
relationship and the point is the "one" side. As before, I'm deferring
on the right side of the diagram (to the right of Identification) to the
taxonomists for now, so let's keep that out of the discussion for the
moment. I have also clarified the diagram by coloring in the actual DwC
classes to distinguish them from selected terms that fall within those
classes (non-colored boxes) and which can be used as properties of
resources that are instances of the class. The two alternatives that
I'm discussion are:
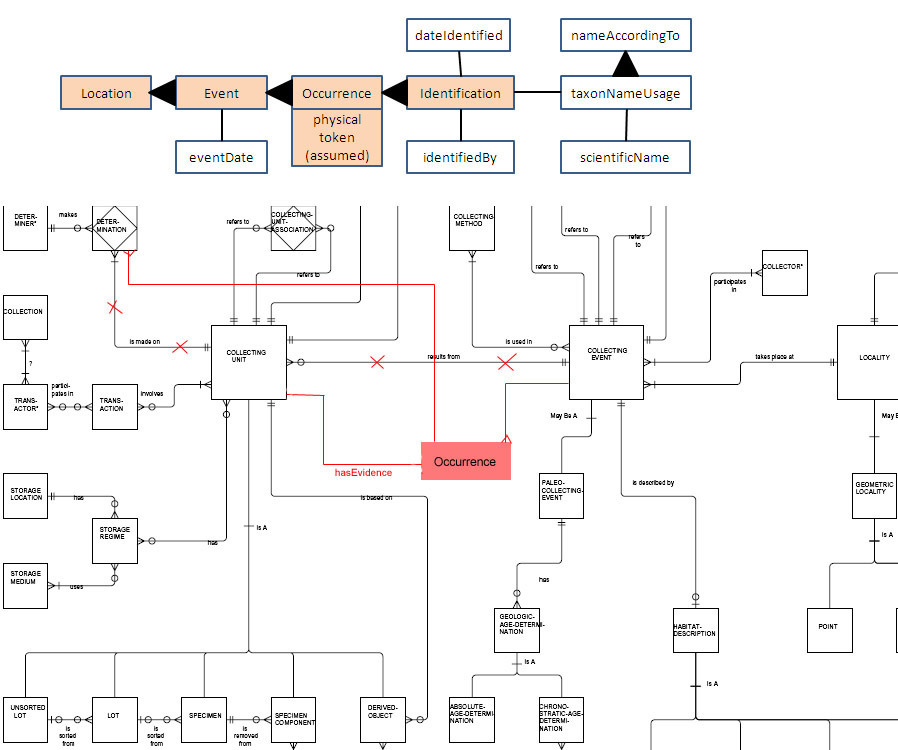
http://bioimages.vanderbilt.edu/pages/token-assumed.gif which I will
refer to as the "assumed token" model and
http://bioimages.vanderbilt.edu/pages/token-explicit.gif which I will
refer to as the "explicit token" model.
I believe that historically the assumed token model has been the one
which most people have had in mind. Before the new DwC standard, we had
specimens and we had observations. In order to avoid redundancies in
terms for those two types of "things", a combined "thing" called
"Occurrence" was created. An Occurrence that was an observation didn't
have a token and an Occurrence that was a specimen had a physical or
living specimen as its token. That's all pretty simple and sensible and
we see evidence of this kind of thinking on the descriptions given
http://rs.tdwg.org/dwc/terms/index.htm . A record for an Occurrence has
a thing called its dwc:basisOfRecord that presumably describes the kind
of token (if any). So if the token were a preserved specimen, we would
say that [Occurrence] basisOfRecord [PreservedSpecimen]. If there were
no token we would say [Occurrence] basisOfRecord [HumanObservation] or
[Occurrence] basisOfRecord [MachineObservation]. Referring back to the
assumed token diagram, in the case of a specimen there is no explicit
reference to the specimen as a separate entity. The terms related to
the specimen, such as preparations and disposition are just plopped into
the Occurrence class which implies that they are properties of the
Occurrence itself.
There seems to be a general consensus that other kinds of tokens can be
used to document an Occurrence. However, the way that the current
Darwin Core terms are designed and placed within classes are very
inconsistent as to how they handle types of tokens other than
specimens. According to the instructions at the top of
http://rs.tdwg.org/dwc/terms/index.htm, a camera trap bird sighting
should have [Occurrence] basisOfRecord [MachineObservation]. It is not
clear how one is supposed to handle the actually metadata for the image
that serves as the token. Unlike specimens where the token's metadata
terms are placed in the Occurrence class, I guess in the case of an
image one is supposed to use associatedMedia to link the so-called
MachineObservation to the image record. If DNA were extracted, one
would link the sequence to the Occurrence using associatedSequences
(although it's not clear to me what the basisOfRecord for that would be
- "TookATissueSample"?). But what does one do for other kinds of
tokens, like seeds or tissue samples - create terms like associatedSeed
and associatedTissueSample? I think that the ResourceRelationship terms
were supposed to handle this problem, but I have yet to see an example
of exactly how this was supposed to work.
As an attempt to resolve this confusion in my mind, I wrote the
Biodiversity Informatics paper that I've promoted frequently on this
list (https://journals.ku.edu/index.php/jbi/article/view/3664) In that
paper, I take the basic assumed token model and broaden it in an attempt
to make the assumed token model work for all kinds of tokens. Because I
assumed that each occurrence has a single token, I "collapsed the
diagram" and connected the properties of the token directly to the
Occurrence resource (as was modeled when specimen properties were placed
within the Occurrence class). If there were several tokens for a given
Individual, I "flattened" the records by creating a separate Occurrence
resource for each token. The model was generalized further by allowing
secondary Occurrence records where the token was not derived directly
from the organism but rather derived from a primary Occurrence record.
In complicated circumstances such as those found in a botanical garden
where a seed or cutting might be collected from a tree with subsequent
generation of a LivingSpecimen which might have a PreservedSpecimen
collected from it and a DigitalStillImage taken of the preserved
specimen. You can see examples of the complex types of situations I
tried to handle at
http://bioimages.vanderbilt.edu/pages/conceptual-scheme-insect.gif and
http://bioimages.vanderbilt.edu/pages/conceptual-scheme-botanical.gif
I created my own terms (like sernec:derivativeOccurrence and
sernec:derivedFrom) to describe the connections among the individual and
the various layers of Occurrences.
Does this system work? Yes, but there are a number of problems
associated with it. The first problem is related to Principle 4 above.
In order for this system to work, there needs to be a consensus in the
DwC community about several things. One is that each Occurrence must
have only one token. If we are going to "type" Occurrences by their
basisOfRecord (and the acceptable values for basisOfRecord are
officially DwC types, see
http://rs.tdwg.org/dwc/terms/type-vocabulary/index.htm) then an
Occurrence can't have two values for basisOfRecord. It is clear from
the discussion we've had that people would like to consider a single
Occurrence to be able to have multiple tokens as documentation. The
second problem is that there needs to be a consensus that a secondary
Occurrence can exist at all (i.e. can you call the image of a specimen
"an Occurrence"?). It is clear to me from the discussion that when
people are thinking about what an Occurrence means, they have in mind
the documentation of the time and place of the Individual in its
environment. In a previous communication, John Wieczorek clarified that
terms describing Occurrences like recordedBy and eventDate should only
apply to primary occurrences and that it would not be appropriate to use
them as properties of what I'm calling a secondary occurrence (such as
the image of a specimen). So I dealt with this by creating a
distinction between Occurrences that document the distribution of a
taxon (using the term sernec:documentsDistribution) and those that
don't. This is something like the old validDistributionFlag, but I
defined documentsDistribution specifically as having a value of "true"
only for Occurrences that were derived directly from the Individual
(gray arrows in the two diagrams from the paper).
But I think that the worst "crime" of the system I suggested is
violation of Principle 5 above. By asserting an unvarying 1:1
relationship between the Occurrence and its token and by collapsing my
relationship diagram to not explicitly include a resource that is the
token itself, I am confusing the USE of an Occurrence (to demonstrate
that a representative of a taxon was present at a particular Location at
a particular time) which what the token IS (a dead organism in a jar or
glued to paper, an electronic representation of photon patterns, a
series of characters representing a nucleotide sequence). So I'm
charging myself with this "crime", pleading guilty, and accepting my
sentence, which is to admit that the system I suggested in the
Biodiversity Informatics paper is "wrong" based on the principles I
outlined above. What this amounts to is an acceptance of the
"rightness" of the explicit token model (in the sense that I defined
"right" in Principle 3 above).
However, if I'm going to make this admission, I demand that the other
guilty parties also confess, namely people who want to assert that
Occurrences have properties that actually are properties of specimens.
If we are going to have a system that actually works, we can't straddle
the fence and say that the assumed token model is correct for specimens
and that the explicit token model is correct for every other kind of
token. If we accept the explicit token model, then specimen will have
to come off of it's throne and be a token like all of the other ways
that we provide evidence that an Occurrence happened. If we accept the
explicit token model, then as a biodiversity informatics resource type
"observation" will have to disappear into a puff of nothingness just
like the "luminescent ether", "centrifugal force", and other kinds of
things that we thought we needed to have to explain things but which
turned out to be unnecessary when we figured out more basic
explanations. A human observation will simply be an Occurrence that
doesn't have a token (which is what I've heard some people say all
along). If we allow the Occurrence/token relationship to be a
one-to-many relationship rather than one-to-one, then HumanObservation
is just the one-to-zero case of the more general one-to-many. For those
of you who like the idea of a "machine observation", that is just an
Occurrence with a token that is whatever type of resource that the
machine produces (electronic data file, image of the organism, image of
a graph, or whatever).
ADVANTAGES OF RECOGNIZING TOKENS EXPLICITLY
If we accept the explicit token model over the assumed token model, a
number of problems get solved. Just as was the case with Events, people
who want to flatten things out by having only one token per Occurrence
can do so. For example, if I want to atomize things by defining my
Occurrence to have taken place during an Event that lasted only the one
second within which my camera shutter clicked, I can do that and have
only a single token associated with that Occurrence. On the other hand,
if others want to define their Occurrence as taking place over the time
over which they photographed, collected a leaf tissue sample, and then
collected a branch of a tree for an herbarium specimen, then they can do
that and associate all of those tokens (one or more images, the tissue
sample, and the preserved specimen) with the single Occurrence.
Another important benefit will come down the line when we actually try
to develop RDF templates. Right now it is not exactly clear (at least
to me) how properties should be divided up among resources that are
being described in the RDF. Based on the assumed token model, I have
been including the metadata for the token within the container element
for the Occurrence. This leads to some of the kind of odd assertions
that people have been objecting to, such as
[Occurrence] dcterms:rights ["(c) 2002 Steven J. Baskauf"] or
[Occurrence] preparations ["skin"].
In the explicit token model, dividing metadata up appropriately among
separate Occurrence and token resources makes more sense, e.g.
[Occurrence] recordedBy ["Joe Curator"]
[image] dcterms:rights ["(c) 2002 Steven J. Baskauf"]
[specimen] preparations ["skin"]
If we wanted to be really explicit about this, we probably should have a
separate class for PhysicalSpecimens and separate the terms that
describe specimens from those that describe Occurrences in general.
There might be some difficulty in doing this because there are some
terms that might be hard to decide about, like catalogNumber. I don't
really think the catalogNumber is a property of the Occurrence, because
it makes more sense to me to say
[specimen] catalogNumber ["12345"] than
[Occurrence] catalogNumber ["12345"]
Realistically, I can't see this kind of separation ever happening, given
the amount of trouble it's been just to get a few people to admit that
Individuals exist. It is just too hard to get motion to happen in the
TDWG community. As a practical matter, people who "compress" the system
(which we admit happens and make concession to in Principle 3) by having
record tables where a single row contains the metadata for both the
Occurrence and the token (i.e. treat it as a 1:1 relationship) will
simply have a column heading for catalogNumber and not care whether the
catalogNumber applies to the Occurrence or the token. It's the people
who want to do the more complicated stuff like simultaneously keep track
of multiple tokens per Occurrence (like several images, a sound
recording, and a specimen), people who want to write RDF, or people who
want to merge databases containing many types of tokens who will have to
pay attention to this distinction. Physical specimens would really be
the only kind of class we would have to create because there already is
a rich vocabulary for media items that is separate from DwC (i.e. the
MRTG schema) and there are probably also vocabularies for stuff like
tissue samples and DNA sequences (although I'm not familiar with them).
TYPING
Bob has warned us about the dangers of asserting that a term always
applies to a certain type of resource by asserting that the term has an
rdfs:domain . However, we should not avoid attempting to assert that a
resource is itself of a certain type. Describing the "type" of a
resource is an important part of letting potential users assess the
possible fitness of use of that resource. For example, you can collect
DNA from a preserved specimen but not from an image. You can include an
image in a print journal article but not a sound recording. You can
create build a range map from Occurrences, but not from DNA samples. In
RDF, one of the basic properties that should be described about every
resource is its rdfs:type . In the generic Linked Data world, you can
pretty much use anything that you want as an rdfs:type . If you decide
to use something obscure, then the danger is that nobody else will have
any idea what kind of thing you are describing. The Draft TDWG GUID
Applicability Statement recommendation 11 says that "Objects in the
biodiversity informatics domain that are identified by a GUID should be
typed using the TDWG ontology or other well-known vocabularies in
accordance with the TDWG common architecture." So in our community, we
can't just type resources any way we want. But exactly how we SHOULD
type things isn't clear. There isn't any functioning TDWG ontology at
the moment. I have found it useful to use the DwC class as the
rdfs:type in my attempts to write RDF. That works pretty well for
things that have DwC classes. But if we follow the explicit token
model, we need to have some consensus on what we will use as the
rdfs:type for the tokens. At this point it looks to me like it would
make sense to have the convention that for tokens one uses either a
dcterms:type or a Darwin Core type (i.e. one of the types listed at
http://rs.tdwg.org/dwc/terms/type-vocabulary/index.htm, although as I
already noted, there is no need for HumanObservation in the case of
describing a token because human observations don't have tokens). There
isn't any sort of "collision" here of the sort that happened right after
the adoption of the Darwin Core Standard when we tried to merge the
Dublin and Darwin Core types (see
http://www.keytonature.eu/wiki/MRTGv08_Type_term_inconsistent_with_DwC and
http://lists.tdwg.org/pipermail/tdwg-content/2009-October/000301.html
with many following responses for the gruesome details) since rdfs:type
doesn't demand any particular type vocabulary. I'm not entirely happy
with this approach because for digital still images the logical type
would be dctype:StillImage, which doesn't give any indication as to
whether the image is film or digital, but I guess at this point in the
21^st century most consuming applications will probably just assume
digital anyway.
So (assuming that Individuals become a DwC class) I guess I don't really
see that there is any problem in using the current Darwin Core classes
to indicate the rdfs:type of every kind of resource that we would be
reasonably likely to assign GUIDs to EXCEPT for tokens. Typing of
tokens could be done using a combination of Darwin Core and Dublin Core
types. What I'm left scratching my head about is basisOfRecord. When I
subscribed to the assumed token model (i.e. when I wrote the
Biodiversity Informatics paper), I thought I knew what basisOfRecord
meant. It meant the kind of token that backed up an Occurrence. So
when I wrote RDF for a specimen (as in
http://bioimages.vanderbilt.edu/rdf/examples/lsu000/0428.rdf) I used the
"hand grenade" approach to typing. I lobbed every kind of "typing" that
I knew of at the Occurrence record for a specimen:
[Occurrence] rdfs:type [dwc:Occurrence]
[Occurrence] dwc:basisOfRecord [dwctype:PreservedSpecimen]
and
[Occurrence] dcterms:type [dctype:PhysicalObject]
Under the explicit token model, I would just use
[Occurrence] rdfs:type [dwc:Occurrence]
for the Occurrence and
[specimen] rdfs:type [dwctype:PreservedSpecimen]
for the specimen itself. If I also took an image at the same time and
wanted to say that it was part of the same Occurrence as the specimen, I
would use
[image] rdfs:type [dctype:StillImage]
Under the explicit token model, I really can't see any use for
dwc:basisOfRecord . Despite the resolution of the "train wreck"
involving dcterms:type that we narrowly avoided after the adoption of
Darwin Core, the definition still says "the specific nature of the data
record - a subtype of the dcterms:type." I think this is clearly wrong
because I think we established that it was NOT a subtype of dcterms:type
in that discussion that I referenced above. So what is
basisOfRecord??? What is "the data record" of which we are describing
the nature? If it's the Occurrence, then I think the consensus that I'm
hearing in the discussion is that an Occurrence data record shouldn't
have as its type any of the dwctype terms except for
dwctype:Occurrence. So what are all of the other terms like
PreservedSpecimen for???
Under the explicit token model, what we really need is NOT
basisOfRecord. What we need is some term like "dwc:tokenID" if you like
the Darwin Core IDREF style or if you prefer the style of the Linked
Data community "dwc:hasToken". In both cases, the object of the term
would be an identifier for the token that's associated with a subject
Occurrence. This term could be applied from zero (for observations) to
many times to an Occurrence. People who want to flatten everything out
will just ignore this term and cram all their metadata for the
Occurrence, token, Event, and Location onto one line in their metadata
table. People who are going to use any kind of one-to-many
relationships at all will have to figure out how to handle that anyway
and won't be daunted by having more than one dwc:tokenID per
Occurrence. In the spirit of the complicated resource relationship
diagrams from my paper, one could link primary tokens (like specimens)
to secondary tokens (like specimen images) by using dwc:tokenID as
well. Any kind of token (primary, secondary, tertiary, ad infinatum)
could be linked to the occurrence that it supports with dwc:occurrenceID.
WHAT DOES THIS DEMAND OF US?
OK, I've now gone on for eight pages of text explaining the rationale
behind the question. So I'll return to the basic question: is the
consensus for modeling the relationship between an Occurrence and
associated token(s) the assumed token model:
http://bioimages.vanderbilt.edu/pages/token-assumed.gif
or the explicit token model:
http://bioimages.vanderbilt.edu/pages/token-explicit.gif
?
If we accept the assumed token model with all of its warts, then for
consistency's sake, we must create dwctype terms for each of the types
of tokens that people would reasonably want to use as evidence for
Occurrences (and my proposal for adding DigitalStillImage as a Darwin
Core type stands). We must also resign ourselves to assigning a
separate occurrence to each token that users want to use to document the
presence of a taxon at a time and place. We also must accept having
goofy-sounding statements like
[Occurrence] dcterms:rights ["(c) 2002 Steven J. Baskauf"]
If we accept the explicit token model, then we need to either dump
basisOfRecord or come up with some rational explanation for what it
actually means (and my proposal to add DigitalStillImage as a Darwin
Core type becomes irrelevant). We also need to create some kind of term
like dwc:tokenID that will allow connections to be made between
Occurrence records and their tokens. For people who want to flatten out
their Occurrence records and put the tokens together with the Occurrence
(i.e. "compress the diagram" to get rid of the token resource), and who
feel some need to indicate the type of the token that they are using,
let them use any appropriate term from the Dublin Core or Darwin Core
types as a value for rdfs:type.
Until we make one of these choices or the other and "fix" Darwin Core to
work in a consistent way, we are just going to continue to misunderstand
each other because each person will just "know an Occurrence when they
see it".
In the interest of space, I am going to defer on explaining my opinions
about LivingSpecimen and establishmentMeans. Those explanations are
contingent on the conclusion that we reach on this issue.
Steve
--
Steven J. Baskauf, Ph.D., Senior Lecturer
Vanderbilt University Dept. of Biological Sciences
postal mail address:
VU Station B 351634
Nashville, TN 37235-1634, U.S.A.
delivery address:
2125 Stevenson Center
1161 21st Ave., S.
Nashville, TN 37235
office: 2128 Stevenson Center
phone: (615) 343-4582, fax: (615) 343-6707
http://bioimages.vanderbilt.edu
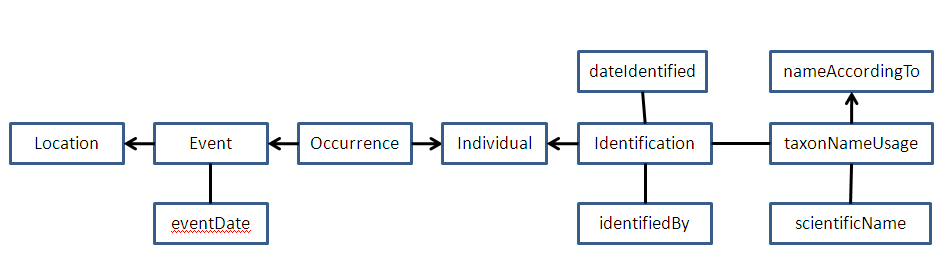{kind=link}
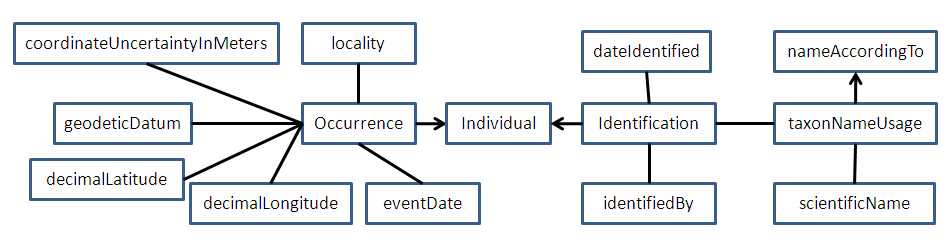{kind=link}
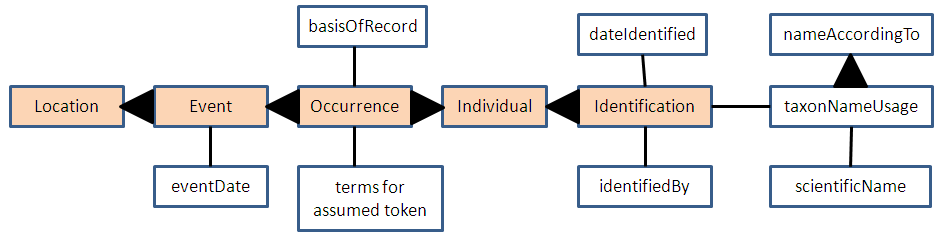{kind=link}
{kind=link}
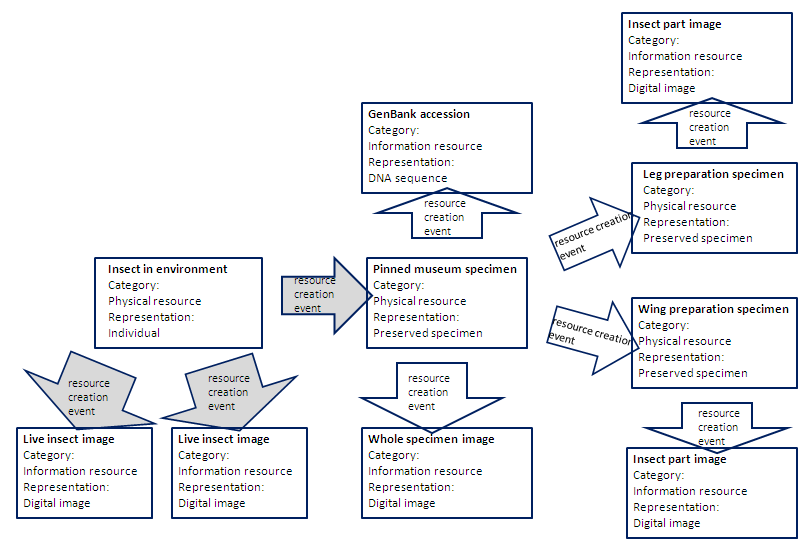{kind=link}
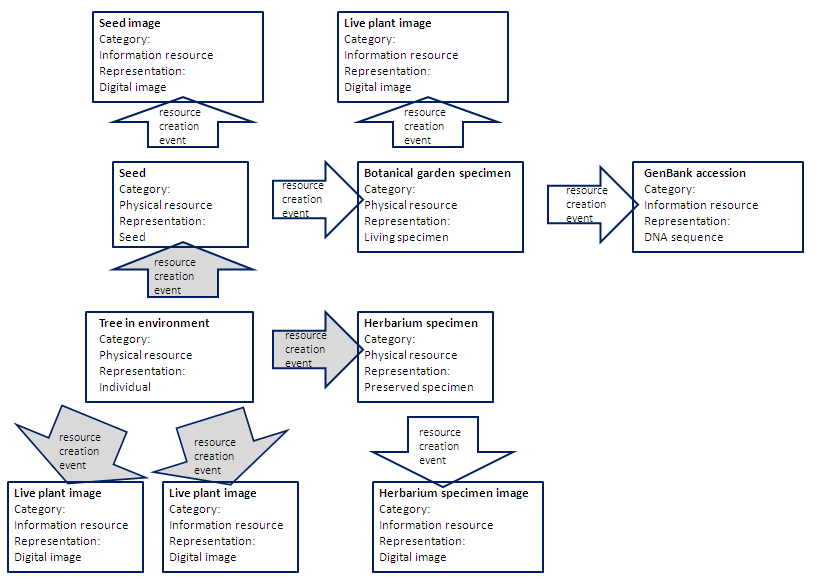{kind=link}
17
71