GUIDs for publications (usages and names)

I was reviewing some of the previous posts on taxon name usages in an attempt to understand them better. I have learned that the Global Names Index is an attempt to catalog taxon names and that it is possible to generate a URI that points to a name there. Is there a parallel effort to do the same thing for literature references? In other words, if I want to describe the TNU: Andropogon virginicus L. sec. Radford et al. (1968) I think I could find a URI GUID for the name Andropogon virginicus . But is there some place where I could find a unique identifier, or better a URL, or best a URI providing RDF/XML for Linnaeus 1753 (the author and publication for the name) and for Radford et al.1968 (the author and publication that expresses the usage I'm intending). I suppose that this question has previously been answered in the in the many posts on taxon names, concepts, etc. However, since usually my brain goes numb and my eyes glaze over in those threads, I probably missed it. Steve -- Steven J. Baskauf, Ph.D., Senior Lecturer Vanderbilt University Dept. of Biological Sciences postal mail address: VU Station B 351634 Nashville, TN 37235-1634, U.S.A. delivery address: 2125 Stevenson Center 1161 21st Ave., S. Nashville, TN 37235 office: 2128 Stevenson Center phone: (615) 343-4582, fax: (615) 343-6707 http://bioimages.vanderbilt.edu

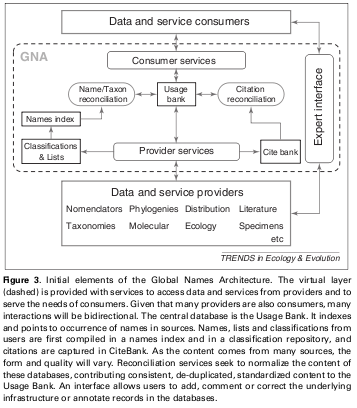
I'm going to hop in here, with a glance toward Richard Pyle and Chris Freeland, to see if they want to disagree with me [ :) ]... I think it's safe to say that some of us are starting to think about that. The attached figure is from: "Patterson, D.J., J. Cooper, P.M. Kirk, R.L. Pyle, and D.P. Remsen (2010) Names are key to the big new biology. Trends in Ecology and Evolution 25(12): 686–691." In the diagram of the GNA/GNI/GNUB architecture, you can see one vertical path for names going from "Classifications & Lists" > Names index > Name/Taxon reconciliation > Usage bank. In parallel, on the right side, is the analogous flow of bibliographic metadata. Right now, a lot more concerted thinking has been put into the left side (the names part) than the right side (the bibliographic citation part). But it's clear both have to happen. The names, of course, come from that cited literature -- they aren't just born floating around in the cloud! Sometime Real Soon Now we're hoping to start defining the use cases, needs, and requirements for that citation (and full-text paper) treatment in a GNA/GNI/GNUB context. Definitely involved will be wrestling with the concept that the bibliographic data for a taxonomic work may well be deserving of a GUID in a way comparable to (but possibly more complex) the need for a GUID (or DOI or somesuch) for a published work itself. -Dean -- Dean Pentcheff pentcheff@gmail.com dpentche@nhm.org On Mon, Jan 3, 2011 at 5:47 PM, Steve Baskauf <steve.baskauf@vanderbilt.edu> wrote:
I was reviewing some of the previous posts on taxon name usages in an attempt to understand them better. I have learned that the Global Names Index is an attempt to catalog taxon names and that it is possible to generate a URI that points to a name there. Is there a parallel effort to do the same thing for literature references? In other words, if I want to describe the TNU: Andropogon virginicus L. sec. Radford et al. (1968) I think I could find a URI GUID for the name Andropogon virginicus . But is there some place where I could find a unique identifier, or better a URL, or best a URI providing RDF/XML for Linnaeus 1753 (the author and publication for the name) and for Radford et al.1968 (the author and publication that expresses the usage I'm intending).
I suppose that this question has previously been answered in the in the many posts on taxon names, concepts, etc. However, since usually my brain goes numb and my eyes glaze over in those threads, I probably missed it.
Steve
-- Steven J. Baskauf, Ph.D., Senior Lecturer Vanderbilt University Dept. of Biological Sciences
postal mail address: VU Station B 351634 Nashville, TN 37235-1634, U.S.A.
delivery address: 2125 Stevenson Center 1161 21st Ave., S. Nashville, TN 37235
office: 2128 Stevenson Center phone: (615) 343-4582, fax: (615) 343-6707 http://bioimages.vanderbilt.edu
_______________________________________________ tdwg-content mailing list tdwg-content@lists.tdwg.org http://lists.tdwg.org/mailman/listinfo/tdwg-content
{kind=link}

But is there some place where I could find a unique identifier, or better a URL, or best a URI providing RDF/XML for Linnaeus 1753 (the author and publication for the name) and for Radford et al.1968 (the author and publication that expresses the usage I'm intending).
Our data here at biodiversity.org.au does exactly this (I can't speak for GNI <g>). If you go to the webpage http://biodiversity.org.au/name/Andropogon%20virginicus.html You'll see that the name has three taxonomic events - the protonym, sensu Vickery (1961), and sensu Cross & Vickery (1950). The name itself has (equivalent) ids http://biodiversity.org.au/apni.name/36530 urn:lsid:biodiversity.org.au:apni.name:36530 each taxon/concept/usage also has its own id. The 1961 usage, for instance, is http://biodiversity.org.au/apni.taxon/118883 urn:lsid:biodiversity.org.au:apni.taxon:118883 We do not have a reference by Radford for this name, but that's a data issue. _______________________________________________ If you have received this transmission in error please notify us immediately by return e-mail and delete all copies. If this e-mail or any attachments have been sent to you in error, that error does not constitute waiver of any confidentiality, privilege or copyright in respect of information in the e-mail or attachments. Please consider the environment before printing this email.

Hi Steve, I have been lobbying the BHL for this for some time. Most recently in this blog post. http://www.taxonconcept.org/taxonconcept-blog/2010/8/5/why-linked-open-data-... What I have realized is that, for many works that are out of copyright, Google books has already scanned and converted them to PDF. You can use these, even extract the relevant PDF pages as long as you keep the Google watermark. This is what I have done for the Cougar. http://lod.taxonconcept.org/ses/v6n7p.html For more recent works you may be able to link to the article PDF. As in this spider example. http://lod.taxonconcept.org/ses/2mqjL.html We also need a URI for to uniquely identify authors and in the absence of a better solution, I have been using, and in some cases creating, entries in Wikipedia which currently has over 5,000 taxonomic author profiles. This results in usable RDF via DBpedia. As you can see in the RDF in this example. http://lod.taxonconcept.org/ses/v6n7p.rdf And in the Knowledge Base < http://lsd.taxonconcept.org/describe/?url=http%3A%2F%2Flod.taxonconcept.org%2Fses%2Fv6n7p%23OriginalDescription> That said, I have also been experimenting with this. http://lod.taxonconcept.org/people/sci_people_1700.rdf About: Carl Linnaeus http://bit.ly/gLgElf - Pete On Mon, Jan 3, 2011 at 7:47 PM, Steve Baskauf <steve.baskauf@vanderbilt.edu>wrote:
I was reviewing some of the previous posts on taxon name usages in an attempt to understand them better. I have learned that the Global Names Index is an attempt to catalog taxon names and that it is possible to generate a URI that points to a name there. Is there a parallel effort to do the same thing for literature references? In other words, if I want to describe the TNU: Andropogon virginicus L. sec. Radford et al. (1968) I think I could find a URI GUID for the name Andropogon virginicus . But is there some place where I could find a unique identifier, or better a URL, or best a URI providing RDF/XML for Linnaeus 1753 (the author and publication for the name) and for Radford et al.1968 (the author and publication that expresses the usage I'm intending).
I suppose that this question has previously been answered in the in the many posts on taxon names, concepts, etc. However, since usually my brain goes numb and my eyes glaze over in those threads, I probably missed it.
Steve
-- Steven J. Baskauf, Ph.D., Senior Lecturer Vanderbilt University Dept. of Biological Sciences
postal mail address: VU Station B 351634 Nashville, TN 37235-1634, U.S.A.
delivery address: 2125 Stevenson Center 1161 21st Ave., S. Nashville, TN 37235
office: 2128 Stevenson Center phone: (615) 343-4582, fax: (615) 343-6707 http://bioimages.vanderbilt.edu
_______________________________________________ tdwg-content mailing list tdwg-content@lists.tdwg.org http://lists.tdwg.org/mailman/listinfo/tdwg-content
-- --------------------------------------------------------------- Pete DeVries Department of Entomology University of Wisconsin - Madison 445 Russell Laboratories 1630 Linden Drive Madison, WI 53706 TaxonConcept Knowledge Base <http://www.taxonconcept.org/> / GeoSpecies Knowledge Base <http://lod.geospecies.org/> About the GeoSpecies Knowledge Base <http://about.geospecies.org/> ------------------------------------------------------------

Steve, Pete, et al., BHL has an OpenURL resolver that can accept a variety of input criteria & return matching records with responses in JSON (with or without callback), XML, HTML, or a direct link. Documentation is here: http://www.biodiversitylibrary.org/openurlhelp.aspx And linked from our broader documentation here: http://biodivlib.wikispaces.com/Developer+Tools+and+API Here's an example, referenced in the documentation, for querying on a monograph/book: http://www.biodiversitylibrary.org/openurl?genre=book&title=Manual+of+No rth+American+Diptera&aufirst=Samuel+Wendell&aulast=Williston&publisher=N ew+Haven+:J.T.+Hathaway,&date=1908&spage=16&format=xml You can also query based on common abbreviations, like Sp. Pl.: http://www.biodiversitylibrary.org/openurl?stitle=Sp.%20Pl.&date=1753&fo rmat=xml MOBOT's Tropicos uses the OpenURL resolver to link to protologues, as in this example: http://www.tropicos.org/Name/2735114 With Tropicos we have an authority record for each journal or monographic title. We match Tropicos' TitleID to BHL's TitleID & use that as a more direct link to the appropriate reference, but still send collation & other info to get to the appropriate page, as in this link: http://www.biodiversitylibrary.org/openurl?pid=title:626&volume=5&issue= &spage=244&date=1830 I know that this is insufficient for zoology & other natural sciences beyond botany, where we need to be able to support citations like "Pallas 1767", which may or may not be preparsed into appropriate fields. A known problem, for sure, and one that we're eager to address, pending funding from NSF. Chris Chris Freeland | Director, Center for Biodiversity Informatics | Missouri Botanical Garden 4344 Shaw Blvd. | St. Louis, Missouri 63110 | 314.577.9548 ________________________________ From: tdwg-content-bounces@lists.tdwg.org [mailto:tdwg-content-bounces@lists.tdwg.org] On Behalf Of Peter DeVries Sent: Tuesday, January 04, 2011 1:33 PM To: Steve Baskauf Cc: tdwg-content@lists.tdwg.org Subject: Re: [tdwg-content] GUIDs for publications (usages and names) Hi Steve, I have been lobbying the BHL for this for some time. Most recently in this blog post. http://www.taxonconcept.org/taxonconcept-blog/2010/8/5/why-linked-open-d ata-makes-sense-for-biodiversity-informatic.html What I have realized is that, for many works that are out of copyright, Google books has already scanned and converted them to PDF. You can use these, even extract the relevant PDF pages as long as you keep the Google watermark. This is what I have done for the Cougar. http://lod.taxonconcept.org/ses/v6n7p.html For more recent works you may be able to link to the article PDF. As in this spider example. http://lod.taxonconcept.org/ses/2mqjL.html We also need a URI for to uniquely identify authors and in the absence of a better solution, I have been using, and in some cases creating, entries in Wikipedia which currently has over 5,000 taxonomic author profiles. This results in usable RDF via DBpedia. As you can see in the RDF in this example. http://lod.taxonconcept.org/ses/v6n7p.rdf And in the Knowledge Base <http://lsd.taxonconcept.org/describe/?url=http%3A%2F%2Flod.taxonconcept .org%2Fses%2Fv6n7p%23OriginalDescription > That said, I have also been experimenting with this. http://lod.taxonconcept.org/people/sci_people_1700.rdf About: Carl Linnaeus http://bit.ly/gLgElf - Pete On Mon, Jan 3, 2011 at 7:47 PM, Steve Baskauf <steve.baskauf@vanderbilt.edu> wrote: I was reviewing some of the previous posts on taxon name usages in an attempt to understand them better. I have learned that the Global Names Index is an attempt to catalog taxon names and that it is possible to generate a URI that points to a name there. Is there a parallel effort to do the same thing for literature references? In other words, if I want to describe the TNU: Andropogon virginicus L. sec. Radford et al. (1968) I think I could find a URI GUID for the name Andropogon virginicus . But is there some place where I could find a unique identifier, or better a URL, or best a URI providing RDF/XML for Linnaeus 1753 (the author and publication for the name) and for Radford et al.1968 (the author and publication that expresses the usage I'm intending). I suppose that this question has previously been answered in the in the many posts on taxon names, concepts, etc. However, since usually my brain goes numb and my eyes glaze over in those threads, I probably missed it. Steve -- Steven J. Baskauf, Ph.D., Senior Lecturer Vanderbilt University Dept. of Biological Sciences postal mail address: VU Station B 351634 Nashville, TN 37235-1634, U.S.A. delivery address: 2125 Stevenson Center 1161 21st Ave., S. Nashville, TN 37235 office: 2128 Stevenson Center phone: (615) 343-4582, fax: (615) 343-6707 http://bioimages.vanderbilt.edu _______________________________________________ tdwg-content mailing list tdwg-content@lists.tdwg.org http://lists.tdwg.org/mailman/listinfo/tdwg-content -- --------------------------------------------------------------- Pete DeVries Department of Entomology University of Wisconsin - Madison 445 Russell Laboratories 1630 Linden Drive Madison, WI 53706 TaxonConcept Knowledge Base <http://www.taxonconcept.org/> / GeoSpecies Knowledge Base <http://lod.geospecies.org/> About the GeoSpecies Knowledge Base <http://about.geospecies.org/> ------------------------------------------------------------
Ooops, to clarify my very last example, we actually would support "Pallas 1767" if properly parsed: http://www.biodiversitylibrary.org/openurl?aulast=Pallas&date=1767&forma t=xml <http://www.biodiversitylibrary.org/openurl?aulast=Pallas&date=1767&form at=xml> What we don't yet support & need to is linking at article citation level. That's where our newly (quietly) launched CiteBank http://citebank.org comes in, and what we're hoping to receive funding to expand. Chris ________________________________ From: tdwg-content-bounces@lists.tdwg.org [mailto:tdwg-content-bounces@lists.tdwg.org] On Behalf Of Chris Freeland Sent: Tuesday, January 04, 2011 1:57 PM To: Peter DeVries; Steve Baskauf Cc: tdwg-content@lists.tdwg.org Subject: Re: [tdwg-content] GUIDs for publications (usages and names) Steve, Pete, et al., BHL has an OpenURL resolver that can accept a variety of input criteria & return matching records with responses in JSON (with or without callback), XML, HTML, or a direct link. Documentation is here: http://www.biodiversitylibrary.org/openurlhelp.aspx And linked from our broader documentation here: http://biodivlib.wikispaces.com/Developer+Tools+and+API Here's an example, referenced in the documentation, for querying on a monograph/book: http://www.biodiversitylibrary.org/openurl?genre=book&title=Manual+of+No rth+American+Diptera&aufirst=Samuel+Wendell&aulast=Williston&publisher=N ew+Haven+:J.T.+Hathaway,&date=1908&spage=16&format=xml You can also query based on common abbreviations, like Sp. Pl.: http://www.biodiversitylibrary.org/openurl?stitle=Sp.%20Pl.&date=1753&fo rmat=xml MOBOT's Tropicos uses the OpenURL resolver to link to protologues, as in this example: http://www.tropicos.org/Name/2735114 With Tropicos we have an authority record for each journal or monographic title. We match Tropicos' TitleID to BHL's TitleID & use that as a more direct link to the appropriate reference, but still send collation & other info to get to the appropriate page, as in this link: http://www.biodiversitylibrary.org/openurl?pid=title:626&volume=5&issue= &spage=244&date=1830 I know that this is insufficient for zoology & other natural sciences beyond botany, where we need to be able to support citations like "Pallas 1767", which may or may not be preparsed into appropriate fields. A known problem, for sure, and one that we're eager to address, pending funding from NSF. Chris Chris Freeland | Director, Center for Biodiversity Informatics | Missouri Botanical Garden 4344 Shaw Blvd. | St. Louis, Missouri 63110 | 314.577.9548 ________________________________ From: tdwg-content-bounces@lists.tdwg.org [mailto:tdwg-content-bounces@lists.tdwg.org] On Behalf Of Peter DeVries Sent: Tuesday, January 04, 2011 1:33 PM To: Steve Baskauf Cc: tdwg-content@lists.tdwg.org Subject: Re: [tdwg-content] GUIDs for publications (usages and names) Hi Steve, I have been lobbying the BHL for this for some time. Most recently in this blog post. http://www.taxonconcept.org/taxonconcept-blog/2010/8/5/why-linked-open-d ata-makes-sense-for-biodiversity-informatic.html What I have realized is that, for many works that are out of copyright, Google books has already scanned and converted them to PDF. You can use these, even extract the relevant PDF pages as long as you keep the Google watermark. This is what I have done for the Cougar. http://lod.taxonconcept.org/ses/v6n7p.html For more recent works you may be able to link to the article PDF. As in this spider example. http://lod.taxonconcept.org/ses/2mqjL.html We also need a URI for to uniquely identify authors and in the absence of a better solution, I have been using, and in some cases creating, entries in Wikipedia which currently has over 5,000 taxonomic author profiles. This results in usable RDF via DBpedia. As you can see in the RDF in this example. http://lod.taxonconcept.org/ses/v6n7p.rdf And in the Knowledge Base <http://lsd.taxonconcept.org/describe/?url=http%3A%2F%2Flod.taxonconcept .org%2Fses%2Fv6n7p%23OriginalDescription > That said, I have also been experimenting with this. http://lod.taxonconcept.org/people/sci_people_1700.rdf About: Carl Linnaeus http://bit.ly/gLgElf - Pete On Mon, Jan 3, 2011 at 7:47 PM, Steve Baskauf <steve.baskauf@vanderbilt.edu> wrote: I was reviewing some of the previous posts on taxon name usages in an attempt to understand them better. I have learned that the Global Names Index is an attempt to catalog taxon names and that it is possible to generate a URI that points to a name there. Is there a parallel effort to do the same thing for literature references? In other words, if I want to describe the TNU: Andropogon virginicus L. sec. Radford et al. (1968) I think I could find a URI GUID for the name Andropogon virginicus . But is there some place where I could find a unique identifier, or better a URL, or best a URI providing RDF/XML for Linnaeus 1753 (the author and publication for the name) and for Radford et al.1968 (the author and publication that expresses the usage I'm intending). I suppose that this question has previously been answered in the in the many posts on taxon names, concepts, etc. However, since usually my brain goes numb and my eyes glaze over in those threads, I probably missed it. Steve -- Steven J. Baskauf, Ph.D., Senior Lecturer Vanderbilt University Dept. of Biological Sciences postal mail address: VU Station B 351634 Nashville, TN 37235-1634, U.S.A. delivery address: 2125 Stevenson Center 1161 21st Ave., S. Nashville, TN 37235 office: 2128 Stevenson Center phone: (615) 343-4582, fax: (615) 343-6707 http://bioimages.vanderbilt.edu _______________________________________________ tdwg-content mailing list tdwg-content@lists.tdwg.org http://lists.tdwg.org/mailman/listinfo/tdwg-content -- --------------------------------------------------------------- Pete DeVries Department of Entomology University of Wisconsin - Madison 445 Russell Laboratories 1630 Linden Drive Madison, WI 53706 TaxonConcept Knowledge Base <http://www.taxonconcept.org/> / GeoSpecies Knowledge Base <http://lod.geospecies.org/> About the GeoSpecies Knowledge Base <http://about.geospecies.org/> ------------------------------------------------------------
Hi Chris, You are missing one of the main benefits of Linked Data. Users do not want to curate their own bibliographic databases and related RDF, they want to simply link to a globally unique, resolvable identifier for that citation. For example: *Felis concolor* Linnaeus 1771 Linnaeus 1771 <= What specific publication is this? "Felis concolor" hasOriginalDescription < http://www.biodiversitylibrary.org/citation/234123412> If the BHL exposed semantic web URI's for each publication, then content experts could search the BHL, find it, and then link to it with a simple resolvable URI. The alternative is that Steve, et al., will create their own identifiers for specific publications, code their own local bibliographic databases. In essence, each group or individual then continues to duplicate the efforts of others. Right now, I have duplicated your functionality in my species concepts. Ideally, I would have done this: <SpeciesConcept> hasOriginalDescription < http://www.biodiversitylibrary.org/citation/234123412> <SpeciesConcept> hasRevisionalDescription < http://www.biodiversitylibrary.org/citation/234124356> Not only are my concepts then linked to your citations, any other data sets that link to your citations are findable. For instance, who else has data sets that link to this citation? To see how this works on the live LOD cloud check out. http://bit.ly/fChHwJ Browse through the related Linked Data Sets - in particular the has close match links. - Pete On Tue, Jan 4, 2011 at 2:31 PM, Chris Freeland <Chris.Freeland@mobot.org>wrote:
Ooops, to clarify my very last example, we actually would support "Pallas 1767" if properly parsed:
* http://www.biodiversitylibrary.org/openurl?aulast=Pallas&date=1767&format=xml *<http://www.biodiversitylibrary.org/openurl?aulast=Pallas&date=1767&format=xml>
What we don't yet support & need to is linking at article citation level. That's where our newly (quietly) launched CiteBank http://citebank.orgcomes in, and what we're hoping to receive funding to expand. Chris ------------------------------ *From:* tdwg-content-bounces@lists.tdwg.org [mailto: tdwg-content-bounces@lists.tdwg.org] *On Behalf Of *Chris Freeland *Sent:* Tuesday, January 04, 2011 1:57 PM *To:* Peter DeVries; Steve Baskauf
*Cc:* tdwg-content@lists.tdwg.org *Subject:* Re: [tdwg-content] GUIDs for publications (usages and names)
Steve, Pete, et al.,
BHL has an OpenURL resolver that can accept a variety of input criteria & return matching records with responses in JSON (with or without callback), XML, HTML, or a direct link. Documentation is here: http://www.biodiversitylibrary.org/openurlhelp.aspx
And linked from our broader documentation here: http://biodivlib.wikispaces.com/Developer+Tools+and+API
Here's an example, referenced in the documentation, for querying on a monograph/book:
You can also query based on common abbreviations, like Sp. Pl.:
http://www.biodiversitylibrary.org/openurl?stitle=Sp.%20Pl.&date=1753&format=xml
MOBOT's Tropicos uses the OpenURL resolver to link to protologues, as in this example: http://www.tropicos.org/Name/2735114
With Tropicos we have an authority record for each journal or monographic title. We match Tropicos' TitleID to BHL's TitleID & use that as a more direct link to the appropriate reference, but still send collation & other info to get to the appropriate page, as in this link:
http://www.biodiversitylibrary.org/openurl?pid=title:626&volume=5&issue=&spage=244&date=1830
I know that this is insufficient for zoology & other natural sciences beyond botany, where we need to be able to support citations like "Pallas 1767", which may or may not be preparsed into appropriate fields. A known problem, for sure, and one that we're eager to address, pending funding from NSF.
Chris
Chris Freeland | Director, Center for Biodiversity Informatics | Missouri Botanical Garden 4344 Shaw Blvd. | St. Louis, Missouri 63110 | 314.577.9548
------------------------------ *From:* tdwg-content-bounces@lists.tdwg.org [mailto: tdwg-content-bounces@lists.tdwg.org] *On Behalf Of *Peter DeVries *Sent:* Tuesday, January 04, 2011 1:33 PM *To:* Steve Baskauf *Cc:* tdwg-content@lists.tdwg.org *Subject:* Re: [tdwg-content] GUIDs for publications (usages and names)
Hi Steve,
I have been lobbying the BHL for this for some time. Most recently in this blog post.
http://www.taxonconcept.org/taxonconcept-blog/2010/8/5/why-linked-open-data-...
What I have realized is that, for many works that are out of copyright, Google books has already scanned and converted them to PDF.
You can use these, even extract the relevant PDF pages as long as you keep the Google watermark.
This is what I have done for the Cougar.
http://lod.taxonconcept.org/ses/v6n7p.html
For more recent works you may be able to link to the article PDF. As in this spider example.
http://lod.taxonconcept.org/ses/2mqjL.html
We also need a URI for to uniquely identify authors and in the absence of a better solution, I have been using, and in some cases creating, entries in Wikipedia which currently has over 5,000 taxonomic author profiles.
This results in usable RDF via DBpedia. As you can see in the RDF in this example.
http://lod.taxonconcept.org/ses/v6n7p.rdf
And in the Knowledge Base < http://lsd.taxonconcept.org/describe/?url=http%3A%2F%2Flod.taxonconcept.org%2Fses%2Fv6n7p%23OriginalDescription>
That said, I have also been experimenting with this.
http://lod.taxonconcept.org/people/sci_people_1700.rdf
About: Carl Linnaeus http://bit.ly/gLgElf
- Pete
On Mon, Jan 3, 2011 at 7:47 PM, Steve Baskauf < steve.baskauf@vanderbilt.edu> wrote:
I was reviewing some of the previous posts on taxon name usages in an attempt to understand them better. I have learned that the Global Names Index is an attempt to catalog taxon names and that it is possible to generate a URI that points to a name there. Is there a parallel effort to do the same thing for literature references? In other words, if I want to describe the TNU: Andropogon virginicus L. sec. Radford et al. (1968) I think I could find a URI GUID for the name Andropogon virginicus . But is there some place where I could find a unique identifier, or better a URL, or best a URI providing RDF/XML for Linnaeus 1753 (the author and publication for the name) and for Radford et al.1968 (the author and publication that expresses the usage I'm intending).
I suppose that this question has previously been answered in the in the many posts on taxon names, concepts, etc. However, since usually my brain goes numb and my eyes glaze over in those threads, I probably missed it.
Steve
-- Steven J. Baskauf, Ph.D., Senior Lecturer Vanderbilt University Dept. of Biological Sciences
postal mail address: VU Station B 351634 Nashville, TN 37235-1634, U.S.A.
delivery address: 2125 Stevenson Center 1161 21st Ave., S. Nashville, TN 37235
office: 2128 Stevenson Center phone: (615) 343-4582, fax: (615) 343-6707 http://bioimages.vanderbilt.edu
_______________________________________________ tdwg-content mailing list tdwg-content@lists.tdwg.org http://lists.tdwg.org/mailman/listinfo/tdwg-content
-- --------------------------------------------------------------- Pete DeVries Department of Entomology University of Wisconsin - Madison 445 Russell Laboratories 1630 Linden Drive Madison, WI 53706 TaxonConcept Knowledge Base <http://www.taxonconcept.org/> / GeoSpecies Knowledge Base <http://lod.geospecies.org/> About the GeoSpecies Knowledge Base <http://about.geospecies.org/> ------------------------------------------------------------
-- --------------------------------------------------------------- Pete DeVries Department of Entomology University of Wisconsin - Madison 445 Russell Laboratories 1630 Linden Drive Madison, WI 53706 TaxonConcept Knowledge Base <http://www.taxonconcept.org/> / GeoSpecies Knowledge Base <http://lod.geospecies.org/> About the GeoSpecies Knowledge Base <http://about.geospecies.org/> ------------------------------------------------------------
A wrinkle on this is that the authority information (name and year) are not the same thing as the actual original publication. Nor is the bibliographic metadata for a publication the same thing as the publication. My hypothesis is that taxonomists (and taxonomy) "want" linkage like this: taxon name ==> correct authority information ==> correct bibliographic metadata ==> actual original publication (full-text) In the general case, you can't determine the authority date by inspection of the actual original publication. You often need external information regarding publication mechanics. (Yes, I know that the date printed on the publication is the correct date of publication for most papers, but anyone who's dealt with taxonomic literature knows that there are many, many exceptions to that.) I'm not sure that they actually want: taxon name ==> actual original publication (full-text) Which is why I start thinking about a GUID for the curated, corrected bibliographic metadata as something distinct from a GUID for the actual publication. -Dean -- Dean Pentcheff pentcheff@gmail.com dpentche@nhm.org On Tue, Jan 4, 2011 at 1:01 PM, Peter DeVries <pete.devries@gmail.com> wrote:
Hi Chris, You are missing one of the main benefits of Linked Data. Users do not want to curate their own bibliographic databases and related RDF, they want to simply link to a globally unique, resolvable identifier for that citation. For example: Felis concolor Linnaeus 1771 Linnaeus 1771 <= What specific publication is this? "Felis concolor" hasOriginalDescription <http://www.biodiversitylibrary.org/citation/234123412> If the BHL exposed semantic web URI's for each publication, then content experts could search the BHL, find it, and then link to it with a simple resolvable URI. The alternative is that Steve, et al., will create their own identifiers for specific publications, code their own local bibliographic databases. In essence, each group or individual then continues to duplicate the efforts of others. Right now, I have duplicated your functionality in my species concepts. Ideally, I would have done this: <SpeciesConcept> hasOriginalDescription <http://www.biodiversitylibrary.org/citation/234123412> <SpeciesConcept> hasRevisionalDescription <http://www.biodiversitylibrary.org/citation/234124356> Not only are my concepts then linked to your citations, any other data sets that link to your citations are findable. For instance, who else has data sets that link to this citation? To see how this works on the live LOD cloud check out. http://bit.ly/fChHwJ Browse through the related Linked Data Sets - in particular the has close match links. - Pete
On Tue, Jan 4, 2011 at 2:31 PM, Chris Freeland <Chris.Freeland@mobot.org> wrote:
Ooops, to clarify my very last example, we actually would support "Pallas 1767" if properly parsed:
http://www.biodiversitylibrary.org/openurl?aulast=Pallas&date=1767&format=xml
What we don't yet support & need to is linking at article citation level. That's where our newly (quietly) launched CiteBank http://citebank.org comes in, and what we're hoping to receive funding to expand.
Chris ________________________________ From: tdwg-content-bounces@lists.tdwg.org [mailto:tdwg-content-bounces@lists.tdwg.org] On Behalf Of Chris Freeland Sent: Tuesday, January 04, 2011 1:57 PM To: Peter DeVries; Steve Baskauf Cc: tdwg-content@lists.tdwg.org Subject: Re: [tdwg-content] GUIDs for publications (usages and names)
Steve, Pete, et al.,
BHL has an OpenURL resolver that can accept a variety of input criteria & return matching records with responses in JSON (with or without callback), XML, HTML, or a direct link. Documentation is here: http://www.biodiversitylibrary.org/openurlhelp.aspx
And linked from our broader documentation here: http://biodivlib.wikispaces.com/Developer+Tools+and+API Here's an example, referenced in the documentation, for querying on a monograph/book:
You can also query based on common abbreviations, like Sp. Pl.:
http://www.biodiversitylibrary.org/openurl?stitle=Sp.%20Pl.&date=1753&format=xml
MOBOT's Tropicos uses the OpenURL resolver to link to protologues, as in this example: http://www.tropicos.org/Name/2735114
With Tropicos we have an authority record for each journal or monographic title. We match Tropicos' TitleID to BHL's TitleID & use that as a more direct link to the appropriate reference, but still send collation & other info to get to the appropriate page, as in this link:
http://www.biodiversitylibrary.org/openurl?pid=title:626&volume=5&issue=&spage=244&date=1830
I know that this is insufficient for zoology & other natural sciences beyond botany, where we need to be able to support citations like "Pallas 1767", which may or may not be preparsed into appropriate fields. A known problem, for sure, and one that we're eager to address, pending funding from NSF.
Chris
Chris Freeland | Director, Center for Biodiversity Informatics | Missouri Botanical Garden 4344 Shaw Blvd. | St. Louis, Missouri 63110 | 314.577.9548
________________________________ From: tdwg-content-bounces@lists.tdwg.org [mailto:tdwg-content-bounces@lists.tdwg.org] On Behalf Of Peter DeVries Sent: Tuesday, January 04, 2011 1:33 PM To: Steve Baskauf Cc: tdwg-content@lists.tdwg.org Subject: Re: [tdwg-content] GUIDs for publications (usages and names)
Hi Steve, I have been lobbying the BHL for this for some time. Most recently in this blog post.
http://www.taxonconcept.org/taxonconcept-blog/2010/8/5/why-linked-open-data-...
What I have realized is that, for many works that are out of copyright, Google books has already scanned and converted them to PDF. You can use these, even extract the relevant PDF pages as long as you keep the Google watermark. This is what I have done for the Cougar. http://lod.taxonconcept.org/ses/v6n7p.html
For more recent works you may be able to link to the article PDF. As in this spider example. http://lod.taxonconcept.org/ses/2mqjL.html
We also need a URI for to uniquely identify authors and in the absence of a better solution, I have been using, and in some cases creating, entries in Wikipedia which currently has over 5,000 taxonomic author profiles. This results in usable RDF via DBpedia. As you can see in the RDF in this example. http://lod.taxonconcept.org/ses/v6n7p.rdf
And in the Knowledge Base
<http://lsd.taxonconcept.org/describe/?url=http%3A%2F%2Flod.taxonconcept.org%...
That said, I have also been experimenting with this. http://lod.taxonconcept.org/people/sci_people_1700.rdf
About: Carl Linnaeus http://bit.ly/gLgElf - Pete On Mon, Jan 3, 2011 at 7:47 PM, Steve Baskauf <steve.baskauf@vanderbilt.edu> wrote:
I was reviewing some of the previous posts on taxon name usages in an attempt to understand them better. I have learned that the Global Names Index is an attempt to catalog taxon names and that it is possible to generate a URI that points to a name there. Is there a parallel effort to do the same thing for literature references? In other words, if I want to describe the TNU: Andropogon virginicus L. sec. Radford et al. (1968) I think I could find a URI GUID for the name Andropogon virginicus . But is there some place where I could find a unique identifier, or better a URL, or best a URI providing RDF/XML for Linnaeus 1753 (the author and publication for the name) and for Radford et al.1968 (the author and publication that expresses the usage I'm intending).
I suppose that this question has previously been answered in the in the many posts on taxon names, concepts, etc. However, since usually my brain goes numb and my eyes glaze over in those threads, I probably missed it.
Steve
-- Steven J. Baskauf, Ph.D., Senior Lecturer Vanderbilt University Dept. of Biological Sciences
postal mail address: VU Station B 351634 Nashville, TN 37235-1634, U.S.A.
delivery address: 2125 Stevenson Center 1161 21st Ave., S. Nashville, TN 37235
office: 2128 Stevenson Center phone: (615) 343-4582, fax: (615) 343-6707 http://bioimages.vanderbilt.edu
_______________________________________________ tdwg-content mailing list tdwg-content@lists.tdwg.org http://lists.tdwg.org/mailman/listinfo/tdwg-content
-- --------------------------------------------------------------- Pete DeVries Department of Entomology University of Wisconsin - Madison 445 Russell Laboratories 1630 Linden Drive Madison, WI 53706 TaxonConcept Knowledge Base / GeoSpecies Knowledge Base About the GeoSpecies Knowledge Base ------------------------------------------------------------
-- --------------------------------------------------------------- Pete DeVries Department of Entomology University of Wisconsin - Madison 445 Russell Laboratories 1630 Linden Drive Madison, WI 53706 TaxonConcept Knowledge Base / GeoSpecies Knowledge Base About the GeoSpecies Knowledge Base ------------------------------------------------------------
_______________________________________________ tdwg-content mailing list tdwg-content@lists.tdwg.org http://lists.tdwg.org/mailman/listinfo/tdwg-content
Hi Dean, We are mixing the finding the correct publication with having the ability to uniquely identify it. What I would like is a system which contains the correct metadata that knowledgable editors could choose and link to. Eventually these links would be made by taxon experts who author or edit the species concepts. My plan would be to have concept authors / editors locate the appropriate article in the BHL and then link to it. I think I have a simple version of what you are describing, but with a fundamental problem.* Here is an example that I believe is correct. http://bit.ly/dWjdJA <http://bit.ly/dWjdJA>The URI itself is http://lod.taxonconcept.org/ses/v6n7p#OriginalDescription *Ideally, these should be done in a way that is independent of the species concept, but my goal is not to create another Linked Data resource for citations. So these are done as metadata included within the species concept RDF document. If you look at that section of the RDF itself. <txn:SpeciesOriginalDescription rdf:about=" http://lod.taxonconcept.org/ses/v6n7p#OriginalDescription"> <!-- Ideally, this should link to a resource in the Biodiversity Heritage Library --> <dcterms:title>Original Published Description relating to Species Concept Puma concolor se:v6n7p</dcterms:title> <dcterms:identifier> http://lod.taxonconcept.org/ses/v6n7p#OriginalDescription </dcterms:identifier> <dcterms:description>LOD metadata about the original species description relating to Species Concept Puma concolor se:v6n7p</dcterms:description> <dcterms:isPartOf rdf:resource=" http://lod.taxonconcept.org/ses/v6n7p#Species"/> <txn:hasAuthorURI rdf:resource=" http://dbpedia.org/resource/Carl_Linnaeus"/> <txn:hasBasionymName>Felis concolor Linnaeus 1771</txn:hasBasionymName> <txn:year>1771</txn:year> <txn:hasPDFVersion rdf:resource=" http://assets.geospecies.org/spec_concept_uuid/603bebac-cc44-4168-bbf7-b11b9... "/> <txn:speciesOriginalDescriptionHasSpeciesConcept rdf:resource=" http://lod.taxonconcept.org/ses/v6n7p#Species"/> <!-- There should be a type specimen. Add link to GBIF via 'txn:sodHasTypeSpecimen' if they know about it. --> <wdrs:describedBy rdf:resource=" http://lod.taxonconcept.org/ses/v6n7p.rdf"/> </txn:SpeciesOriginalDescription> Here is an example that is currently a placeholder for the original description but links to what the Harvard DB believes is the type specimen for *Stereopalpus vestitus *(Say 1824) <txn:SpeciesOriginalDescription rdf:about=" http://lod.taxonconcept.org/ses/MYQMc#OriginalDescription"> <!-- Ideally, this should link to a resource in the Biodiversity Heritage Library --> <dcterms:title>Original Published Description relating to Species Concept Stereopalpus vestitus se:MYQMc</dcterms:title> <dcterms:identifier> http://lod.taxonconcept.org/ses/MYQMc#OriginalDescription </dcterms:identifier> <dcterms:description>LOD metadata about the original species description relating to Species Concept Stereopalpus vestitus se:MYQMc</dcterms:description> <dcterms:isPartOf rdf:resource=" http://lod.taxonconcept.org/ses/MYQMc#Species"/> <txn:hasAuthorURI rdf:resource="http://dbpedia.org/resource/Thomas_Say "/> <txn:year>1824</txn:year> <txn:speciesOriginalDescriptionHasSpeciesConcept rdf:resource=" http://lod.taxonconcept.org/ses/MYQMc#Species"/> <!-- There should be a type specimen. Add link to GBIF via 'txn:sodHasTypeSpecimen' if they know about it. --> <txn:hasEtypePage rdf:resource=" http://mcz-28168.oeb.harvard.edu/mcz/FMPro?-DB=Image.fm&-Lay=web&-Fo... "/> <wdrs:describedBy rdf:resource=" http://lod.taxonconcept.org/ses/MYQMc.rdf"/> </txn:SpeciesOriginalDescription> Respectfully, - Pete On Tue, Jan 4, 2011 at 5:02 PM, Dean Pentcheff <pentcheff@gmail.com> wrote:
A wrinkle on this is that the authority information (name and year) are not the same thing as the actual original publication. Nor is the bibliographic metadata for a publication the same thing as the publication.
My hypothesis is that taxonomists (and taxonomy) "want" linkage like this: taxon name ==> correct authority information ==> correct bibliographic metadata ==> actual original publication (full-text)
In the general case, you can't determine the authority date by inspection of the actual original publication. You often need external information regarding publication mechanics. (Yes, I know that the date printed on the publication is the correct date of publication for most papers, but anyone who's dealt with taxonomic literature knows that there are many, many exceptions to that.)
I'm not sure that they actually want: taxon name ==> actual original publication (full-text)
Which is why I start thinking about a GUID for the curated, corrected bibliographic metadata as something distinct from a GUID for the actual publication.
-Dean -- Dean Pentcheff pentcheff@gmail.com dpentche@nhm.org
Hi Chris, You are missing one of the main benefits of Linked Data. Users do not want to curate their own bibliographic databases and related RDF, they want to simply link to a globally unique, resolvable identifier for that citation. For example: Felis concolor Linnaeus 1771 Linnaeus 1771 <= What specific publication is this? "Felis concolor" hasOriginalDescription <http://www.biodiversitylibrary.org/citation/234123412> If the BHL exposed semantic web URI's for each publication, then content experts could search the BHL, find it, and then link to it with a simple resolvable URI. The alternative is that Steve, et al., will create their own identifiers for specific publications, code their own local bibliographic databases. In essence, each group or individual then continues to duplicate the efforts of others. Right now, I have duplicated your functionality in my species concepts. Ideally, I would have done this: <SpeciesConcept> hasOriginalDescription <http://www.biodiversitylibrary.org/citation/234123412> <SpeciesConcept> hasRevisionalDescription < http://www.biodiversitylibrary.org/citation/234124356> Not only are my concepts then linked to your citations, any other data sets that link to your citations are findable. For instance, who else has data sets that link to this citation? To see how this works on the live LOD cloud check out. http://bit.ly/fChHwJ Browse through the related Linked Data Sets - in particular the has close match links. - Pete
On Tue, Jan 4, 2011 at 2:31 PM, Chris Freeland <Chris.Freeland@mobot.org
wrote:
Ooops, to clarify my very last example, we actually would support
"Pallas
1767" if properly parsed:
http://www.biodiversitylibrary.org/openurl?aulast=Pallas&date=1767&format=xml
What we don't yet support & need to is linking at article citation
level.
That's where our newly (quietly) launched CiteBank http://citebank.orgcomes in, and what we're hoping to receive funding to expand.
Chris ________________________________ From: tdwg-content-bounces@lists.tdwg.org [mailto:tdwg-content-bounces@lists.tdwg.org] On Behalf Of Chris Freeland Sent: Tuesday, January 04, 2011 1:57 PM To: Peter DeVries; Steve Baskauf Cc: tdwg-content@lists.tdwg.org Subject: Re: [tdwg-content] GUIDs for publications (usages and names)
Steve, Pete, et al.,
BHL has an OpenURL resolver that can accept a variety of input criteria & return matching records with responses in JSON (with or without callback), XML, HTML, or a direct link. Documentation is here: http://www.biodiversitylibrary.org/openurlhelp.aspx
And linked from our broader documentation here: http://biodivlib.wikispaces.com/Developer+Tools+and+API Here's an example, referenced in the documentation, for querying on a monograph/book:
You can also query based on common abbreviations, like Sp. Pl.:
http://www.biodiversitylibrary.org/openurl?stitle=Sp.%20Pl.&date=1753&format=xml
MOBOT's Tropicos uses the OpenURL resolver to link to protologues, as in this example: http://www.tropicos.org/Name/2735114
With Tropicos we have an authority record for each journal or
monographic
title. We match Tropicos' TitleID to BHL's TitleID & use that as a more direct link to the appropriate reference, but still send collation & other info to get to the appropriate page, as in this link:
http://www.biodiversitylibrary.org/openurl?pid=title:626&volume=5&issue=&spage=244&date=1830
I know that this is insufficient for zoology & other natural sciences beyond botany, where we need to be able to support citations like
"Pallas
1767", which may or may not be preparsed into appropriate fields. A known problem, for sure, and one that we're eager to address, pending funding from NSF.
Chris
Chris Freeland | Director, Center for Biodiversity Informatics | Missouri Botanical Garden 4344 Shaw Blvd. | St. Louis, Missouri 63110 | 314.577.9548
________________________________ From: tdwg-content-bounces@lists.tdwg.org [mailto:tdwg-content-bounces@lists.tdwg.org] On Behalf Of Peter DeVries Sent: Tuesday, January 04, 2011 1:33 PM To: Steve Baskauf Cc: tdwg-content@lists.tdwg.org Subject: Re: [tdwg-content] GUIDs for publications (usages and names)
Hi Steve, I have been lobbying the BHL for this for some time. Most recently in
blog post.
http://www.taxonconcept.org/taxonconcept-blog/2010/8/5/why-linked-open-data-...
What I have realized is that, for many works that are out of copyright, Google books has already scanned and converted them to PDF. You can use these, even extract the relevant PDF pages as long as you
keep
the Google watermark. This is what I have done for the Cougar. http://lod.taxonconcept.org/ses/v6n7p.html
For more recent works you may be able to link to the article PDF. As in this spider example. http://lod.taxonconcept.org/ses/2mqjL.html
We also need a URI for to uniquely identify authors and in the absence of a better solution, I have been using, and in some cases creating, entries in Wikipedia which currently has over 5,000 taxonomic author profiles. This results in usable RDF via DBpedia. As you can see in the RDF in
On Tue, Jan 4, 2011 at 1:01 PM, Peter DeVries <pete.devries@gmail.com> wrote: this this
example. http://lod.taxonconcept.org/ses/v6n7p.rdf
And in the Knowledge Base
< http://lsd.taxonconcept.org/describe/?url=http%3A%2F%2Flod.taxonconcept.org%...
That said, I have also been experimenting with this. http://lod.taxonconcept.org/people/sci_people_1700.rdf
About: Carl Linnaeus http://bit.ly/gLgElf - Pete On Mon, Jan 3, 2011 at 7:47 PM, Steve Baskauf <steve.baskauf@vanderbilt.edu> wrote:
I was reviewing some of the previous posts on taxon name usages in an attempt to understand them better. I have learned that the Global
Names
Index is an attempt to catalog taxon names and that it is possible to generate a URI that points to a name there. Is there a parallel effort to do the same thing for literature references? In other words, if I want to describe the TNU: Andropogon virginicus L. sec. Radford et al. (1968) I think I could find a URI GUID for the name Andropogon virginicus . But is there some place where I could find a unique identifier, or better a URL, or best a URI providing RDF/XML for Linnaeus 1753 (the author and publication for the name) and for Radford et al.1968 (the author and publication that expresses the usage I'm intending).
I suppose that this question has previously been answered in the in the many posts on taxon names, concepts, etc. However, since usually my brain goes numb and my eyes glaze over in those threads, I probably missed it.
Steve
-- Steven J. Baskauf, Ph.D., Senior Lecturer Vanderbilt University Dept. of Biological Sciences
postal mail address: VU Station B 351634 Nashville, TN 37235-1634, U.S.A.
delivery address: 2125 Stevenson Center 1161 21st Ave., S. Nashville, TN 37235
office: 2128 Stevenson Center phone: (615) 343-4582, fax: (615) 343-6707 http://bioimages.vanderbilt.edu
_______________________________________________ tdwg-content mailing list tdwg-content@lists.tdwg.org http://lists.tdwg.org/mailman/listinfo/tdwg-content
-- --------------------------------------------------------------- Pete DeVries Department of Entomology University of Wisconsin - Madison 445 Russell Laboratories 1630 Linden Drive Madison, WI 53706 TaxonConcept Knowledge Base / GeoSpecies Knowledge Base About the GeoSpecies Knowledge Base ------------------------------------------------------------
-- --------------------------------------------------------------- Pete DeVries Department of Entomology University of Wisconsin - Madison 445 Russell Laboratories 1630 Linden Drive Madison, WI 53706 TaxonConcept Knowledge Base / GeoSpecies Knowledge Base About the GeoSpecies Knowledge Base ------------------------------------------------------------
_______________________________________________ tdwg-content mailing list tdwg-content@lists.tdwg.org http://lists.tdwg.org/mailman/listinfo/tdwg-content
-- --------------------------------------------------------------- Pete DeVries Department of Entomology University of Wisconsin - Madison 445 Russell Laboratories 1630 Linden Drive Madison, WI 53706 TaxonConcept Knowledge Base <http://www.taxonconcept.org/> / GeoSpecies Knowledge Base <http://lod.geospecies.org/> About the GeoSpecies Knowledge Base <http://about.geospecies.org/> ------------------------------------------------------------

Hi all, Basically I agree with Dean when he writes: <snip> My hypothesis is that taxonomists (and taxonomy) "want" linkage like this: taxon name ==> correct authority information ==> correct bibliographic metadata ==> actual original publication (full-text) </snip> However there is probably an intermediate step, too, namely "Brief citation (Nomenclator Style)" or similar, e.g. for the first entry in my IRMNG genera list: Genus: Aa Authority: Baker, 1940 Brief citation (from Nomenclator Zoologicus): Bull. Bishop Mus., 165, 107, 108. Original Publication: Baker, H. B. (1940). Zonitid snails from Pacific Islands. Part 2. Hawaiian genera of Microcystinae. Bull. Bishop Mus., 165: 103-291. Online link (as available): xxxxx (The full publication details would ideally be atomised further as required i.e. author, stated publication year, article title, journal titles, etc.) For a large number of names this type of brief citation is all that is readily available in present bulk data compilations (typically nomenclators for animal and plant names), but ideally can be expanded to a full citation retrospectively and as time / resources are available. I have not looked at CiteBank as yet but recall hearing that it would accommodate both types. Of course the article details would most likely be more re-useable for many purposes than the brief citation (including individual page ref/s) as the latter will typically apply only to a single name initial publication instance whereas the whole work will contain a lot more and better fit the "enter once, use many times" rationale of giving things identifiers suitable for re-use. Regards - Tony ________________________________________ From: tdwg-content-bounces@lists.tdwg.org [tdwg-content-bounces@lists.tdwg.org] On Behalf Of Dean Pentcheff [pentcheff@gmail.com] Sent: Wednesday, 5 January 2011 10:02 AM To: tdwg-content@lists.tdwg.org Cc: Chris Freeland Subject: Re: [tdwg-content] GUIDs for publications (usages and names) A wrinkle on this is that the authority information (name and year) are not the same thing as the actual original publication. Nor is the bibliographic metadata for a publication the same thing as the publication. My hypothesis is that taxonomists (and taxonomy) "want" linkage like this: taxon name ==> correct authority information ==> correct bibliographic metadata ==> actual original publication (full-text) In the general case, you can't determine the authority date by inspection of the actual original publication. You often need external information regarding publication mechanics. (Yes, I know that the date printed on the publication is the correct date of publication for most papers, but anyone who's dealt with taxonomic literature knows that there are many, many exceptions to that.) I'm not sure that they actually want: taxon name ==> actual original publication (full-text) Which is why I start thinking about a GUID for the curated, corrected bibliographic metadata as something distinct from a GUID for the actual publication. -Dean -- Dean Pentcheff pentcheff@gmail.com dpentche@nhm.org On Tue, Jan 4, 2011 at 1:01 PM, Peter DeVries <pete.devries@gmail.com> wrote:
Hi Chris, You are missing one of the main benefits of Linked Data. Users do not want to curate their own bibliographic databases and related RDF, they want to simply link to a globally unique, resolvable identifier for that citation. For example: Felis concolor Linnaeus 1771 Linnaeus 1771 <= What specific publication is this? "Felis concolor" hasOriginalDescription <http://www.biodiversitylibrary.org/citation/234123412> If the BHL exposed semantic web URI's for each publication, then content experts could search the BHL, find it, and then link to it with a simple resolvable URI. The alternative is that Steve, et al., will create their own identifiers for specific publications, code their own local bibliographic databases. In essence, each group or individual then continues to duplicate the efforts of others. Right now, I have duplicated your functionality in my species concepts. Ideally, I would have done this: <SpeciesConcept> hasOriginalDescription <http://www.biodiversitylibrary.org/citation/234123412> <SpeciesConcept> hasRevisionalDescription <http://www.biodiversitylibrary.org/citation/234124356> Not only are my concepts then linked to your citations, any other data sets that link to your citations are findable. For instance, who else has data sets that link to this citation? To see how this works on the live LOD cloud check out. http://bit.ly/fChHwJ Browse through the related Linked Data Sets - in particular the has close match links. - Pete
On Tue, Jan 4, 2011 at 2:31 PM, Chris Freeland <Chris.Freeland@mobot.org> wrote:
Ooops, to clarify my very last example, we actually would support "Pallas 1767" if properly parsed:
http://www.biodiversitylibrary.org/openurl?aulast=Pallas&date=1767&format=xml
What we don't yet support & need to is linking at article citation level. That's where our newly (quietly) launched CiteBank http://citebank.org comes in, and what we're hoping to receive funding to expand.
Chris ________________________________ From: tdwg-content-bounces@lists.tdwg.org [mailto:tdwg-content-bounces@lists.tdwg.org] On Behalf Of Chris Freeland Sent: Tuesday, January 04, 2011 1:57 PM To: Peter DeVries; Steve Baskauf Cc: tdwg-content@lists.tdwg.org Subject: Re: [tdwg-content] GUIDs for publications (usages and names)
Steve, Pete, et al.,
BHL has an OpenURL resolver that can accept a variety of input criteria & return matching records with responses in JSON (with or without callback), XML, HTML, or a direct link. Documentation is here: http://www.biodiversitylibrary.org/openurlhelp.aspx
And linked from our broader documentation here: http://biodivlib.wikispaces.com/Developer+Tools+and+API Here's an example, referenced in the documentation, for querying on a monograph/book:
You can also query based on common abbreviations, like Sp. Pl.:
http://www.biodiversitylibrary.org/openurl?stitle=Sp.%20Pl.&date=1753&format=xml
MOBOT's Tropicos uses the OpenURL resolver to link to protologues, as in this example: http://www.tropicos.org/Name/2735114
With Tropicos we have an authority record for each journal or monographic title. We match Tropicos' TitleID to BHL's TitleID & use that as a more direct link to the appropriate reference, but still send collation & other info to get to the appropriate page, as in this link:
http://www.biodiversitylibrary.org/openurl?pid=title:626&volume=5&issue=&spage=244&date=1830
I know that this is insufficient for zoology & other natural sciences beyond botany, where we need to be able to support citations like "Pallas 1767", which may or may not be preparsed into appropriate fields. A known problem, for sure, and one that we're eager to address, pending funding from NSF.
Chris
Chris Freeland | Director, Center for Biodiversity Informatics | Missouri Botanical Garden 4344 Shaw Blvd. | St. Louis, Missouri 63110 | 314.577.9548
________________________________ From: tdwg-content-bounces@lists.tdwg.org [mailto:tdwg-content-bounces@lists.tdwg.org] On Behalf Of Peter DeVries Sent: Tuesday, January 04, 2011 1:33 PM To: Steve Baskauf Cc: tdwg-content@lists.tdwg.org Subject: Re: [tdwg-content] GUIDs for publications (usages and names)
Hi Steve, I have been lobbying the BHL for this for some time. Most recently in this blog post.
http://www.taxonconcept.org/taxonconcept-blog/2010/8/5/why-linked-open-data-...
What I have realized is that, for many works that are out of copyright, Google books has already scanned and converted them to PDF. You can use these, even extract the relevant PDF pages as long as you keep the Google watermark. This is what I have done for the Cougar. http://lod.taxonconcept.org/ses/v6n7p.html
For more recent works you may be able to link to the article PDF. As in this spider example. http://lod.taxonconcept.org/ses/2mqjL.html
We also need a URI for to uniquely identify authors and in the absence of a better solution, I have been using, and in some cases creating, entries in Wikipedia which currently has over 5,000 taxonomic author profiles. This results in usable RDF via DBpedia. As you can see in the RDF in this example. http://lod.taxonconcept.org/ses/v6n7p.rdf
And in the Knowledge Base
<http://lsd.taxonconcept.org/describe/?url=http%3A%2F%2Flod.taxonconcept.org%...
That said, I have also been experimenting with this. http://lod.taxonconcept.org/people/sci_people_1700.rdf
About: Carl Linnaeus http://bit.ly/gLgElf - Pete On Mon, Jan 3, 2011 at 7:47 PM, Steve Baskauf <steve.baskauf@vanderbilt.edu> wrote:
I was reviewing some of the previous posts on taxon name usages in an attempt to understand them better. I have learned that the Global Names Index is an attempt to catalog taxon names and that it is possible to generate a URI that points to a name there. Is there a parallel effort to do the same thing for literature references? In other words, if I want to describe the TNU: Andropogon virginicus L. sec. Radford et al. (1968) I think I could find a URI GUID for the name Andropogon virginicus . But is there some place where I could find a unique identifier, or better a URL, or best a URI providing RDF/XML for Linnaeus 1753 (the author and publication for the name) and for Radford et al.1968 (the author and publication that expresses the usage I'm intending).
I suppose that this question has previously been answered in the in the many posts on taxon names, concepts, etc. However, since usually my brain goes numb and my eyes glaze over in those threads, I probably missed it.
Steve
-- Steven J. Baskauf, Ph.D., Senior Lecturer Vanderbilt University Dept. of Biological Sciences
postal mail address: VU Station B 351634 Nashville, TN 37235-1634, U.S.A.
delivery address: 2125 Stevenson Center 1161 21st Ave., S. Nashville, TN 37235
office: 2128 Stevenson Center phone: (615) 343-4582, fax: (615) 343-6707 http://bioimages.vanderbilt.edu
_______________________________________________ tdwg-content mailing list tdwg-content@lists.tdwg.org http://lists.tdwg.org/mailman/listinfo/tdwg-content
-- --------------------------------------------------------------- Pete DeVries Department of Entomology University of Wisconsin - Madison 445 Russell Laboratories 1630 Linden Drive Madison, WI 53706 TaxonConcept Knowledge Base / GeoSpecies Knowledge Base About the GeoSpecies Knowledge Base ------------------------------------------------------------
-- --------------------------------------------------------------- Pete DeVries Department of Entomology University of Wisconsin - Madison 445 Russell Laboratories 1630 Linden Drive Madison, WI 53706 TaxonConcept Knowledge Base / GeoSpecies Knowledge Base About the GeoSpecies Knowledge Base ------------------------------------------------------------
_______________________________________________ tdwg-content mailing list tdwg-content@lists.tdwg.org http://lists.tdwg.org/mailman/listinfo/tdwg-content
_______________________________________________ tdwg-content mailing list tdwg-content@lists.tdwg.org http://lists.tdwg.org/mailman/listinfo/tdwg-content
Thanks for all of the responses to my original question. They have given me much food for thought. I will throw out several comments that have come to mind as a result. 1. With regards to what Dean and Tony have said about the kind of "linkage" that taxonomists want:
My hypothesis is that taxonomists (and taxonomy) "want" linkage like this: taxon name ==> correct authority information ==> correct bibliographic metadata ==> actual original publication (full-text)
Although a linkage to a full text version of the publication would be nice, it's not really what I wanted/needed when I posed the original question. As a non-taxonomist, I've absorbed the point which has been made repeatedly that in an Identification which simply provides a taxon name is inadequate and that we should be specifying a taxon name usage (i.e. name sensu publication, or name sec. publication). So I'm more interested in a globally unique and reusable identifiers for names, publications, and their intersections as TNUs. As such, I don't care that much whether there is a linkage to a pdf of the publication as long as I can refer to the TNU by a GUID and somebody else knows exactly what taxon usage I'm talking about. I don't have a high degree of confidence in using text strings like "Andropogon virginicus L. sec. Radford et al. (1968)" as identifiers for TNUs because all it takes is one missing period, no parentheses, or an extra space and then I have a different string from somebody else. If the GUID is going to be a URI, then I'd really like it to be dereferenceable to RDF. In the event that the Linked Data world comes together, that gets me out of the business of thrashing with all of the taxonomy stuff that I'm not interested in doing myself. I believe that this is exactly one of the points that Pete was trying to make. From this standpoint, what Paul illustrated in his example of http://biodiversity.org.au/apni.taxon/118883 is exactly what I had in mind: a URI for the taxon/TNU/concept with RDF links to the URI for the name and the URI for the publication. The "fundamental problem" (recognized by Pete with his asterisk) is that most of these URIs don't yet exist and it would be counterproductive for a bunch of different people to start "minting" them on their own. I certainly don't have the interest or ability to do it and I doubt that Paul has time to create them all for the rest of us on the planet at biodiversity.org.au . This should be large scale/community effort. I was disappointed to see that although http://citebank.org seems to be positioning itself as such a large-scale effort, I can't see any evidence that it is planning to create "Linked Data-ready" URIs that are subject to content negotiation (or did I just miss it?). I think that is probably a mistake. Making a GUID that could be used in the LOD world doesn't force anybody to subscribe to the LOD model, but making a GUID that is not suitable for LOD will cause those who are interested in Linked Data to look elsewhere. 2. On the subject of DOIs, I discovered what Paul mentioned in his post: there doesn't seem to be any easy way to search for a DOI or to know if a DOI exists for a publication. Another problem is who would pay for the DOIs that would need to be created for all of the obscure, out of print publications that would need to be put into the system? (I believe that there is some per-item cost for DOIs, right?) Generic HTTP URIs seem like an easier solution. 3. Another issue which I think should be mentioned in the context of this discussion is that I don't think that it is a good idea to blur the distinction between a URL pointing to an information resource (such as a pdf or jpg file) and a URI that is serving as a GUID. If an information resource URL were considered a GUID, then I believe that it would be bad practice to ever change even a single byte of the particular file to which that URL is pointing. It would also be difficult to achieve content negotiation (i.e. to provide either a human-readable representation or a machine-readable RDF file when requested) if a specific file format is specified in the URL. So even if there were a PDF available for a publication online, the URL of that PDF shouldn't be used as a GUID. It would be better to represent the publication as a non-information resource and use a seeAlso link to the pdf representation. I think what I've said here has bearing on Dean's message (directly below). In particular I think that the statement "a GUID for the curated, corrected bibliographic metadata as something distinct from a GUID for the actual publication." makes an artificial distinction between a publication and its metadata. I think the correct approach is to consider that the GUID represents the publication as a conceptual entity (i.e. non-information resource) which has properties that can be described by the bibilographic metadata, and which can have a representation as a pdf, jpg image, etc. With that approach, the GUID can be an unchanging identifier for the publication while the metadata and representations associated with it can be free to be corrected, updated, or improved. Steve
________________________________________ From: tdwg-content-bounces@lists.tdwg.org [tdwg-content-bounces@lists.tdwg.org] On Behalf Of Dean Pentcheff [pentcheff@gmail.com] Sent: Wednesday, 5 January 2011 10:02 AM To: tdwg-content@lists.tdwg.org Cc: Chris Freeland Subject: Re: [tdwg-content] GUIDs for publications (usages and names)
A wrinkle on this is that the authority information (name and year) are not the same thing as the actual original publication. Nor is the bibliographic metadata for a publication the same thing as the publication.
My hypothesis is that taxonomists (and taxonomy) "want" linkage like this: taxon name ==> correct authority information ==> correct bibliographic metadata ==> actual original publication (full-text)
In the general case, you can't determine the authority date by inspection of the actual original publication. You often need external information regarding publication mechanics. (Yes, I know that the date printed on the publication is the correct date of publication for most papers, but anyone who's dealt with taxonomic literature knows that there are many, many exceptions to that.)
I'm not sure that they actually want: taxon name ==> actual original publication (full-text)
Which is why I start thinking about a GUID for the curated, corrected bibliographic metadata as something distinct from a GUID for the actual publication.
-Dean -- Dean Pentcheff pentcheff@gmail.com dpentche@nhm.org
On Tue, Jan 4, 2011 at 1:01 PM, Peter DeVries <pete.devries@gmail.com> wrote:
Hi Chris, You are missing one of the main benefits of Linked Data. Users do not want to curate their own bibliographic databases and related RDF, they want to simply link to a globally unique, resolvable identifier for that citation. For example: Felis concolor Linnaeus 1771 Linnaeus 1771 <= What specific publication is this? "Felis concolor" hasOriginalDescription <http://www.biodiversitylibrary.org/citation/234123412> If the BHL exposed semantic web URI's for each publication, then content experts could search the BHL, find it, and then link to it with a simple resolvable URI. The alternative is that Steve, et al., will create their own identifiers for specific publications, code their own local bibliographic databases. In essence, each group or individual then continues to duplicate the efforts of others. Right now, I have duplicated your functionality in my species concepts. Ideally, I would have done this: <SpeciesConcept> hasOriginalDescription <http://www.biodiversitylibrary.org/citation/234123412> <SpeciesConcept> hasRevisionalDescription <http://www.biodiversitylibrary.org/citation/234124356> Not only are my concepts then linked to your citations, any other data sets that link to your citations are findable. For instance, who else has data sets that link to this citation? To see how this works on the live LOD cloud check out. http://bit.ly/fChHwJ Browse through the related Linked Data Sets - in particular the has close match links. - Pete
On Tue, Jan 4, 2011 at 2:31 PM, Chris Freeland <Chris.Freeland@mobot.org> wrote:
Ooops, to clarify my very last example, we actually would support "Pallas 1767" if properly parsed:
http://www.biodiversitylibrary.org/openurl?aulast=Pallas&date=1767&format=xml
What we don't yet support & need to is linking at article citation level. That's where our newly (quietly) launched CiteBank http://citebank.org comes in, and what we're hoping to receive funding to expand.
Chris ________________________________ From: tdwg-content-bounces@lists.tdwg.org [mailto:tdwg-content-bounces@lists.tdwg.org] On Behalf Of Chris Freeland Sent: Tuesday, January 04, 2011 1:57 PM To: Peter DeVries; Steve Baskauf Cc: tdwg-content@lists.tdwg.org Subject: Re: [tdwg-content] GUIDs for publications (usages and names)
Steve, Pete, et al.,
BHL has an OpenURL resolver that can accept a variety of input criteria & return matching records with responses in JSON (with or without callback), XML, HTML, or a direct link. Documentation is here: http://www.biodiversitylibrary.org/openurlhelp.aspx
And linked from our broader documentation here: http://biodivlib.wikispaces.com/Developer+Tools+and+API Here's an example, referenced in the documentation, for querying on a monograph/book:
You can also query based on common abbreviations, like Sp. Pl.:
http://www.biodiversitylibrary.org/openurl?stitle=Sp.%20Pl.&date=1753&format=xml
MOBOT's Tropicos uses the OpenURL resolver to link to protologues, as in this example: http://www.tropicos.org/Name/2735114
With Tropicos we have an authority record for each journal or monographic title. We match Tropicos' TitleID to BHL's TitleID & use that as a more direct link to the appropriate reference, but still send collation & other info to get to the appropriate page, as in this link:
http://www.biodiversitylibrary.org/openurl?pid=title:626&volume=5&issue=&spage=244&date=1830
I know that this is insufficient for zoology & other natural sciences beyond botany, where we need to be able to support citations like "Pallas 1767", which may or may not be preparsed into appropriate fields. A known problem, for sure, and one that we're eager to address, pending funding from NSF.
Chris
Chris Freeland | Director, Center for Biodiversity Informatics | Missouri Botanical Garden 4344 Shaw Blvd. | St. Louis, Missouri 63110 | 314.577.9548
________________________________ From: tdwg-content-bounces@lists.tdwg.org [mailto:tdwg-content-bounces@lists.tdwg.org] On Behalf Of Peter DeVries Sent: Tuesday, January 04, 2011 1:33 PM To: Steve Baskauf Cc: tdwg-content@lists.tdwg.org Subject: Re: [tdwg-content] GUIDs for publications (usages and names)
Hi Steve, I have been lobbying the BHL for this for some time. Most recently in this blog post.
http://www.taxonconcept.org/taxonconcept-blog/2010/8/5/why-linked-open-data-...
What I have realized is that, for many works that are out of copyright, Google books has already scanned and converted them to PDF. You can use these, even extract the relevant PDF pages as long as you keep the Google watermark. This is what I have done for the Cougar. http://lod.taxonconcept.org/ses/v6n7p.html
For more recent works you may be able to link to the article PDF. As in this spider example. http://lod.taxonconcept.org/ses/2mqjL.html
We also need a URI for to uniquely identify authors and in the absence of a better solution, I have been using, and in some cases creating, entries in Wikipedia which currently has over 5,000 taxonomic author profiles. This results in usable RDF via DBpedia. As you can see in the RDF in this example. http://lod.taxonconcept.org/ses/v6n7p.rdf
And in the Knowledge Base
<http://lsd.taxonconcept.org/describe/?url=http%3A%2F%2Flod.taxonconcept.org%...
That said, I have also been experimenting with this. http://lod.taxonconcept.org/people/sci_people_1700.rdf
About: Carl Linnaeus http://bit.ly/gLgElf - Pete On Mon, Jan 3, 2011 at 7:47 PM, Steve Baskauf <steve.baskauf@vanderbilt.edu> wrote:
I was reviewing some of the previous posts on taxon name usages in an attempt to understand them better. I have learned that the Global Names Index is an attempt to catalog taxon names and that it is possible to generate a URI that points to a name there. Is there a parallel effort to do the same thing for literature references? In other words, if I want to describe the TNU: Andropogon virginicus L. sec. Radford et al. (1968) I think I could find a URI GUID for the name Andropogon virginicus . But is there some place where I could find a unique identifier, or better a URL, or best a URI providing RDF/XML for Linnaeus 1753 (the author and publication for the name) and for Radford et al.1968 (the author and publication that expresses the usage I'm intending).
I suppose that this question has previously been answered in the in the many posts on taxon names, concepts, etc. However, since usually my brain goes numb and my eyes glaze over in those threads, I probably missed it.
Steve
-- Steven J. Baskauf, Ph.D., Senior Lecturer Vanderbilt University Dept. of Biological Sciences
postal mail address: VU Station B 351634 Nashville, TN 37235-1634, U.S.A.
delivery address: 2125 Stevenson Center 1161 21st Ave., S. Nashville, TN 37235
office: 2128 Stevenson Center phone: (615) 343-4582, fax: (615) 343-6707 http://bioimages.vanderbilt.edu
_______________________________________________ tdwg-content mailing list tdwg-content@lists.tdwg.org http://lists.tdwg.org/mailman/listinfo/tdwg-content
-- --------------------------------------------------------------- Pete DeVries Department of Entomology University of Wisconsin - Madison 445 Russell Laboratories 1630 Linden Drive Madison, WI 53706 TaxonConcept Knowledge Base / GeoSpecies Knowledge Base About the GeoSpecies Knowledge Base ------------------------------------------------------------
-- --------------------------------------------------------------- Pete DeVries Department of Entomology University of Wisconsin - Madison 445 Russell Laboratories 1630 Linden Drive Madison, WI 53706 TaxonConcept Knowledge Base / GeoSpecies Knowledge Base About the GeoSpecies Knowledge Base ------------------------------------------------------------
_______________________________________________ tdwg-content mailing list tdwg-content@lists.tdwg.org http://lists.tdwg.org/mailman/listinfo/tdwg-content
_______________________________________________ tdwg-content mailing list tdwg-content@lists.tdwg.org http://lists.tdwg.org/mailman/listinfo/tdwg-content _______________________________________________ tdwg-content mailing list tdwg-content@lists.tdwg.org http://lists.tdwg.org/mailman/listinfo/tdwg-content .
-- Steven J. Baskauf, Ph.D., Senior Lecturer Vanderbilt University Dept. of Biological Sciences postal mail address: VU Station B 351634 Nashville, TN 37235-1634, U.S.A. delivery address: 2125 Stevenson Center 1161 21st Ave., S. Nashville, TN 37235 office: 2128 Stevenson Center phone: (615) 343-4582, fax: (615) 343-6707 http://bioimages.vanderbilt.edu

Few quick comments on this thread. DOIs ---- CrossRef provides an OpenURL resolver for discovering whether a DOI exists for a publication. This is how publishers find DOIs for references cited in manuscripts, and several bibliographic tools use it to populate their databases (e.g., Zotero, Mendeley). I provide a wrapper to this resolver at http://bioguid.info/openurl. The number of taxonomic works with DOIs is growing, and may be rather larger than most people realise, especially as publishers such as Wiley's digitise archives of society journals, and as JSTOR increases its content. Add yes, CSIRO uses DOIs. The "brief citations" Tony mentions, which are widely used by nomenclators, do pose problems for services such as CrossRef. I discuss one approach to solving this in my paper "bioGUID: resolving, discovering, and minting identifiers for biodiversity informatics" (http://dx.doi.org/10.1186/1471-2105-10-S14-S5 ), where I describe a service that takes a page within a reference and tries to locate the DOI for the enclosing paper. I'm using this service at the moment to find papers in the recently released Plant List. OCLC ---- Paul mentions http://www.worldcat.org, which is a great resource, albeit riddled with duplicates (although the library world has its own notion of what counts as a duplicate). BHL content is now appearing in OCLC. CiteBank -------- As Steve points out, we're going to need a large community effort to assemble a bibliography of all taxonomic work. Without wishing to side track this thread, I think this is a task best undertaken with a much larger community than we traditionally think of. The bibliographic site Mendeley or something similar, such as Zotero, seem better bets than doing this ourselves. Linked Data ----------- Without wishing to get too bogged down in a discussion of linked data, perhaps a few points are worth noting. 1. Although DOIs currently don't play nice with linked data (unless wrapped in a service such as http://bioguid), according to Geoff Bilder, CrossRef has plans to add content negotiation and RDF to http://dx.doi.org , and is close to flicking the switch to make this happen. 2. The bulk of linked data resources for biology are not provided by the primary data sources (e.g., GenBank or PubMed) but by third party wrappers around those services. These services have made choices about URIs, vocabularies that might not hold if and when the primary data providers, such as NCBI, start serving RDF. In my experience these third party services may also omit things that we may think of as vital, for example http://bio2rdf.org doesn't include specimen or locality information for GenBank sequences. 3. For many resources we either have no linked data URIs or too many. This either leads to somebody having to mint URIs, typically for something that isn't their own data (e.g., I provide HTTP URIs for ISSNs), or having to accommodate multiple URIs, which makes specifying relationships between objects rather tricky (one database may describe a citation link between two documents using PubMed identifiers, while another describes the same link using DOIs). My point is that linked data isn't a panacea, in some respects it just makes the mess we're in easier to see. The hope of the linked data community is that eventually it will all come together. For an alternative take on this I recommend Stefano Mazzocchi's essay "On Data Reconciliation Strategies and Their Impact on the Web of Data" http://www.betaversion.org/~stefano/linotype/news/304/ Regards Rod --------------------------------------------------------- Roderic Page Professor of Taxonomy Institute of Biodiversity, Animal Health and Comparative Medicine College of Medical, Veterinary and Life Sciences Graham Kerr Building University of Glasgow Glasgow G12 8QQ, UK Email: r.page@bio.gla.ac.uk Tel: +44 141 330 4778 Fax: +44 141 330 2792 AIM: rodpage1962@aim.com Facebook: http://www.facebook.com/profile.php?id=1112517192 Twitter: http://twitter.com/rdmpage Blog: http://iphylo.blogspot.com Home page: http://taxonomy.zoology.gla.ac.uk/rod/rod.html
And following on re: DOIs, BHL has become a member of CrossRef and starting in February will begin assigning DOIs first to our monographs & then on to journal content. There is an annual fee for membership and then a fee for every DOI assigned. BHL is absorbing these costs for community benefit. Chris -----Original Message----- From: tdwg-content-bounces@lists.tdwg.org on behalf of Roderic Page Sent: Wed 1/5/2011 2:17 AM To: tdwg-content@lists.tdwg.org Cc: Paul Murray; Chris Freeland Subject: Re: [tdwg-content] GUIDs for publications (usages and names) Few quick comments on this thread. DOIs ---- CrossRef provides an OpenURL resolver for discovering whether a DOI exists for a publication. This is how publishers find DOIs for references cited in manuscripts, and several bibliographic tools use it to populate their databases (e.g., Zotero, Mendeley). I provide a wrapper to this resolver at http://bioguid.info/openurl. The number of taxonomic works with DOIs is growing, and may be rather larger than most people realise, especially as publishers such as Wiley's digitise archives of society journals, and as JSTOR increases its content. Add yes, CSIRO uses DOIs. The "brief citations" Tony mentions, which are widely used by nomenclators, do pose problems for services such as CrossRef. I discuss one approach to solving this in my paper "bioGUID: resolving, discovering, and minting identifiers for biodiversity informatics" (http://dx.doi.org/10.1186/1471-2105-10-S14-S5 ), where I describe a service that takes a page within a reference and tries to locate the DOI for the enclosing paper. I'm using this service at the moment to find papers in the recently released Plant List. OCLC ---- Paul mentions http://www.worldcat.org, which is a great resource, albeit riddled with duplicates (although the library world has its own notion of what counts as a duplicate). BHL content is now appearing in OCLC. CiteBank -------- As Steve points out, we're going to need a large community effort to assemble a bibliography of all taxonomic work. Without wishing to side track this thread, I think this is a task best undertaken with a much larger community than we traditionally think of. The bibliographic site Mendeley or something similar, such as Zotero, seem better bets than doing this ourselves. Linked Data ----------- Without wishing to get too bogged down in a discussion of linked data, perhaps a few points are worth noting. 1. Although DOIs currently don't play nice with linked data (unless wrapped in a service such as http://bioguid), according to Geoff Bilder, CrossRef has plans to add content negotiation and RDF to http://dx.doi.org , and is close to flicking the switch to make this happen. 2. The bulk of linked data resources for biology are not provided by the primary data sources (e.g., GenBank or PubMed) but by third party wrappers around those services. These services have made choices about URIs, vocabularies that might not hold if and when the primary data providers, such as NCBI, start serving RDF. In my experience these third party services may also omit things that we may think of as vital, for example http://bio2rdf.org doesn't include specimen or locality information for GenBank sequences. 3. For many resources we either have no linked data URIs or too many. This either leads to somebody having to mint URIs, typically for something that isn't their own data (e.g., I provide HTTP URIs for ISSNs), or having to accommodate multiple URIs, which makes specifying relationships between objects rather tricky (one database may describe a citation link between two documents using PubMed identifiers, while another describes the same link using DOIs). My point is that linked data isn't a panacea, in some respects it just makes the mess we're in easier to see. The hope of the linked data community is that eventually it will all come together. For an alternative take on this I recommend Stefano Mazzocchi's essay "On Data Reconciliation Strategies and Their Impact on the Web of Data" http://www.betaversion.org/~stefano/linotype/news/304/ Regards Rod --------------------------------------------------------- Roderic Page Professor of Taxonomy Institute of Biodiversity, Animal Health and Comparative Medicine College of Medical, Veterinary and Life Sciences Graham Kerr Building University of Glasgow Glasgow G12 8QQ, UK Email: r.page@bio.gla.ac.uk Tel: +44 141 330 4778 Fax: +44 141 330 2792 AIM: rodpage1962@aim.com Facebook: http://www.facebook.com/profile.php?id=1112517192 Twitter: http://twitter.com/rdmpage Blog: http://iphylo.blogspot.com Home page: http://taxonomy.zoology.gla.ac.uk/rod/rod.html _______________________________________________ tdwg-content mailing list tdwg-content@lists.tdwg.org http://lists.tdwg.org/mailman/listinfo/tdwg-content
On 5 Jan 2011, at 15:25, Chris Freeland wrote:
And following on re: DOIs, BHL has become a member of CrossRef and starting in February will begin assigning DOIs first to our monographs & then on to journal content. There is an annual fee for membership and then a fee for every DOI assigned. BHL is absorbing these costs for community benefit.
Chris
V. cool! Regards Rod --------------------------------------------------------- Roderic Page Professor of Taxonomy Institute of Biodiversity, Animal Health and Comparative Medicine College of Medical, Veterinary and Life Sciences Graham Kerr Building University of Glasgow Glasgow G12 8QQ, UK Email: r.page@bio.gla.ac.uk Tel: +44 141 330 4778 Fax: +44 141 330 2792 AIM: rodpage1962@aim.com Facebook: http://www.facebook.com/profile.php?id=1112517192 Twitter: http://twitter.com/rdmpage Blog: http://iphylo.blogspot.com Home page: http://taxonomy.zoology.gla.ac.uk/rod/rod.html

I second Rod's "V. cool!" proclamation! I think this has the potential to solve a lot of problems with DOIs (particularly for the old literature). It doesn't solve all the problems (e.g., we still need to define the article-level units within BHL content, and we'll still need to establish a system of GUIDs that can be applied to sub-article units, such as treatments), but in the vast majority of cases, the DOIs will be the ticket into the services of CrossRef. I desperately want to comment on several points made in this thread (which I've only read just now), but I'm currently travelling, so I'll chime in later. Aloha, Rich P.S. Question for Rod/Chris/anyone else concerning DOIs: Does the annual fee only apply to the ability to mint DOIs within a given year, or does it also apply to resolving them? Put another way, if BHL stops paying its annual fee sometime in the future, will the already-minted DOI's be resolvable into perpetuity, or will they stop being resolved at that point? From: tdwg-content-bounces@lists.tdwg.org [mailto:tdwg-content-bounces@lists.tdwg.org] On Behalf Of Roderic Page Sent: Wednesday, January 05, 2011 5:42 AM To: Chris Freeland Cc: tdwg-content@lists.tdwg.org; Paul Murray Subject: Re: [tdwg-content] GUIDs for publications (usages and names) On 5 Jan 2011, at 15:25, Chris Freeland wrote: And following on re: DOIs, BHL has become a member of CrossRef and starting in February will begin assigning DOIs first to our monographs & then on to journal content. There is an annual fee for membership and then a fee for every DOI assigned. BHL is absorbing these costs for community benefit. Chris V. cool! Regards Rod --------------------------------------------------------- Roderic Page Professor of Taxonomy Institute of Biodiversity, Animal Health and Comparative Medicine College of Medical, Veterinary and Life Sciences Graham Kerr Building University of Glasgow Glasgow G12 8QQ, UK Email: r.page@bio.gla.ac.uk Tel: +44 141 330 4778 Fax: +44 141 330 2792 AIM: rodpage1962@aim.com Facebook: http://www.facebook.com/profile.php?id=1112517192 Twitter: http://twitter.com/rdmpage Blog: http://iphylo.blogspot.com Home page: http://taxonomy.zoology.gla.ac.uk/rod/rod.html
Rich, Concerning your perpetuity/sustainability questions, DOIs can be transferred from one organization to another should something happen to the journal/publisher/organization that minted the DOI in the first place. Also, DOIs live on in perpetuity should the organization discontinue its membership. It's also my understanding that if CrossRef (as but one of several DOI registration agencies) goes out of business then the DOIs continue to be resolved via the International DOI Foundation, just without all the bibliometric services that CrossRef provides (this cites that, this has been cited n times). That's the reason for the per-piece charge - you're buying into a resolution service for that object & its identifier that considers persistence over time to be of paramount importance. Chris ________________________________ From: Richard Pyle [mailto:deepreef@bishopmuseum.org] Sent: Wednesday, January 05, 2011 10:43 AM To: 'Roderic Page'; Chris Freeland Cc: tdwg-content@lists.tdwg.org; 'Paul Murray' Subject: RE: [tdwg-content] GUIDs for publications (usages and names) I second Rod's "V. cool!" proclamation! I think this has the potential to solve a lot of problems with DOIs (particularly for the old literature). It doesn't solve all the problems (e.g., we still need to define the article-level units within BHL content, and we'll still need to establish a system of GUIDs that can be applied to sub-article units, such as treatments), but in the vast majority of cases, the DOIs will be the ticket into the services of CrossRef. I desperately want to comment on several points made in this thread (which I've only read just now), but I'm currently travelling, so I'll chime in later. Aloha, Rich P.S. Question for Rod/Chris/anyone else concerning DOIs: Does the annual fee only apply to the ability to mint DOIs within a given year, or does it also apply to resolving them? Put another way, if BHL stops paying its annual fee sometime in the future, will the already-minted DOI's be resolvable into perpetuity, or will they stop being resolved at that point? From: tdwg-content-bounces@lists.tdwg.org [mailto:tdwg-content-bounces@lists.tdwg.org] On Behalf Of Roderic Page Sent: Wednesday, January 05, 2011 5:42 AM To: Chris Freeland Cc: tdwg-content@lists.tdwg.org; Paul Murray Subject: Re: [tdwg-content] GUIDs for publications (usages and names) On 5 Jan 2011, at 15:25, Chris Freeland wrote: And following on re: DOIs, BHL has become a member of CrossRef and starting in February will begin assigning DOIs first to our monographs & then on to journal content. There is an annual fee for membership and then a fee for every DOI assigned. BHL is absorbing these costs for community benefit. Chris V. cool! Regards Rod --------------------------------------------------------- Roderic Page Professor of Taxonomy Institute of Biodiversity, Animal Health and Comparative Medicine College of Medical, Veterinary and Life Sciences Graham Kerr Building University of Glasgow Glasgow G12 8QQ, UK Email: r.page@bio.gla.ac.uk Tel: +44 141 330 4778 Fax: +44 141 330 2792 AIM: rodpage1962@aim.com Facebook: http://www.facebook.com/profile.php?id=1112517192 Twitter: http://twitter.com/rdmpage Blog: http://iphylo.blogspot.com Home page: http://taxonomy.zoology.gla.ac.uk/rod/rod.html
Rich et al, My thinking has been that the Semantic Web only began to take off when pragmatists started to have more influence than the often described "white coated ontologists". In one way, the "white coated ontologists" are right, but their over-engineered solutions really only worked within their specific model of the world. Now that the pragmatists have more influence, people are marking up huge amounts of data and the issues of how to get these different vocabularies and datasets to work well together is being discussed and worked out on the public-lod email list. I think the best way to proceed is to get some example data sets online, and then work out how to get them to work together in a useful way. An initial step is to connect them using predicates *like* skos:closeMatch etc. Then we should work within the larger LOD / Semantic Web community to fix whatever problems we find. In some cases this will result in a change in other vocabularies like foaf or skos. The problems that some of us see in these have been noticed by others and it makes sense that we come to some common solution. In other cases it will involve getting the rest of the LOD community to adopt, or at least work well with, those vocabulary terms we propose. This is to the benefit of our community because it makes the tools and data made available by others usable by us. It also might be useful to step back and ask. *How successful have taxonomists been in getting the rest of the scientific community to adopt their standards?* My current thinking is that we can deal with DOI's and LSID's if we define predicates that allow consuming applications to recognize that the "object" is to be interpreted as a DOI-like or LSID-like "thing". And do this in a way that will be widely adopted. It is my understanding that Virtuoso is the only triple / quadstore / sparql endpoint that knows how to handle LSIDs. Also, although I like a lot of what Steve says, I think that most existing crawlers expect that a seeAlso link is to some html, xml, rdf type thing and will not be able to handle a multi-megabyte PDF. This is why I reluctantly minted the predicate "hasPDF" Also some services like Sindice seem to be able to interpret predicates that are defined as subproperties of well known predicates. For instance "txn:hasWikipediaArticle" etc. are subproperties of foaf:page. We also need some sort of "playground" knowledge base where related data sets can be loaded and tested to see how well they work together. It is for this reason that I created the SPARQL endpoint described here: http://www.taxonconcept.org/sparql-endpoint/ I did a quick look at the apni data and my initial impression is that I like it. Two sites I used to check it were: http://inspector.sindice.com/ and http://validator.linkeddata.org/vapour To get a better idea of how it works etc., I also loaded a small sample of the RDF into my knowledge base. I had not expected that there would be a related TaxonConcept entity since I have limited myself to mainly US plants, but after checking I found that the example emailed earlier had a related entity in TaxonConcept. So I made up this page to make it easier for people to browse through the related data. Gail K. reminded me that some email clients handle the "#" in some URL's differently. To end users these appear as broken links. Here is the page with links to the small set of APNI RDF and the related entity in TaxonConcept. http://lod.taxonconcept.org/apni_example.html Respectfully, - Pete On Wed, Jan 5, 2011 at 10:43 AM, Richard Pyle <deepreef@bishopmuseum.org>wrote:
I second Rod’s “V. cool!” proclamation! I think this has the potential to solve a lot of problems with DOIs (particularly for the old literature). It doesn’t solve all the problems (e.g., we still need to define the article-level units within BHL content, and we’ll still need to establish a system of GUIDs that can be applied to sub-article units, such as treatments), but in the vast majority of cases, the DOIs will be the ticket into the services of CrossRef.
I desperately want to comment on several points made in this thread (which I’ve only read just now), but I’m currently travelling, so I’ll chime in later.
Aloha,
Rich
P.S. Question for Rod/Chris/anyone else concerning DOIs: Does the annual fee only apply to the ability to mint DOIs within a given year, or does it also apply to resolving them? Put another way, if BHL stops paying its annual fee sometime in the future, will the already-minted DOI’s be resolvable into perpetuity, or will they stop being resolved at that point?
*From:* tdwg-content-bounces@lists.tdwg.org [mailto: tdwg-content-bounces@lists.tdwg.org] *On Behalf Of *Roderic Page *Sent:* Wednesday, January 05, 2011 5:42 AM *To:* Chris Freeland *Cc:* tdwg-content@lists.tdwg.org; Paul Murray
*Subject:* Re: [tdwg-content] GUIDs for publications (usages and names)
On 5 Jan 2011, at 15:25, Chris Freeland wrote:
And following on re: DOIs, BHL has become a member of CrossRef and starting in February will begin assigning DOIs first to our monographs & then on to journal content. There is an annual fee for membership and then a fee for every DOI assigned. BHL is absorbing these costs for community benefit.
Chris
V. cool!
Regards
Rod
---------------------------------------------------------
Roderic Page
Professor of Taxonomy
Institute of Biodiversity, Animal Health and Comparative Medicine
College of Medical, Veterinary and Life Sciences
Graham Kerr Building
University of Glasgow
Glasgow G12 8QQ, UK
Email: r.page@bio.gla.ac.uk
Tel: +44 141 330 4778
Fax: +44 141 330 2792
AIM: rodpage1962@aim.com
Facebook: http://www.facebook.com/profile.php?id=1112517192
Twitter: http://twitter.com/rdmpage
Blog: http://iphylo.blogspot.com
Home page: http://taxonomy.zoology.gla.ac.uk/rod/rod.html
_______________________________________________ tdwg-content mailing list tdwg-content@lists.tdwg.org http://lists.tdwg.org/mailman/listinfo/tdwg-content
-- --------------------------------------------------------------- Pete DeVries Department of Entomology University of Wisconsin - Madison 445 Russell Laboratories 1630 Linden Drive Madison, WI 53706 TaxonConcept Knowledge Base <http://www.taxonconcept.org/> / GeoSpecies Knowledge Base <http://lod.geospecies.org/> About the GeoSpecies Knowledge Base <http://about.geospecies.org/> ------------------------------------------------------------
On 06/01/2011, at 7:48 AM, Peter DeVries wrote:
Also, although I like a lot of what Steve says, I think that most existing crawlers expect that a seeAlso link is to some html, xml, rdf type thing and will not be able to handle a multi-megabyte PDF.
This is why I reluctantly minted the predicate "hasPDF"
Hmm. This is an issue with linkeddata: when you fetch a URI while crawling the semantic web, if it redirects, then it's an "other resource" and you get RDF. If not, then you are potentially pulling a multimegabyte "information resource" across the wire. A solution is to use an HTTP "HEAD" request when you do the initial URI fetch. If it's an "other resource", the HEAD return will be a 303 and contain redirect that you want in the "Location" header, and that's all you need. If not, the 200 result will contain the content type and possibly even the size, which is what you need to know before you GET it. So .. the problem that "hasPDF" is meant to address might be addressable by the crawlers just being a bit smarter about how they browse the semweb. _______________________________________________ If you have received this transmission in error please notify us immediately by return e-mail and delete all copies. If this e-mail or any attachments have been sent to you in error, that error does not constitute waiver of any confidentiality, privilege or copyright in respect of information in the e-mail or attachments. Please consider the environment before printing this email.
I suspect that the major crawlers have better error handling, but I have used Elmo from OpenRDF.org. It does not have very robust error handling. It will try to pull in anything in it's whitelist that is linked via seeAlso, and fail if it is a PDF. I have not tried Virtuoso for data crawling since I have worked out other ways to get RDF, but I suspect that it does a much better job. Most groups now make their data available as an RDF dump which eliminated the need to crawl if you want to pull in a lot of data. I guess the question is do you want to use a generic seeAlso which most crawlers follow, vs some more specific predicate that says "here is the PDF" My reluctance was more about minting my own vs. finding some other vocabulary which has a similar predicate. With the *hasPDF* predicate it would be pretty easy to query for all species concepts that have a linked original description PDF etc. I suspect that some standard predicate will eventually become accepted since it is very useful to have something more specific than foaf:Document. Respectively, - Pete On Wed, Jan 5, 2011 at 6:54 PM, Paul Murray <pmurray@anbg.gov.au> wrote:
On 06/01/2011, at 7:48 AM, Peter DeVries wrote:
Also, although I like a lot of what Steve says, I think that most existing crawlers expect that a seeAlso link is to some html, xml, rdf type thing and will not be able to handle a multi-megabyte PDF.
This is why I reluctantly minted the predicate "hasPDF"
Hmm. This is an issue with linkeddata: when you fetch a URI while crawling the semantic web, if it redirects, then it's an "other resource" and you get RDF. If not, then you are potentially pulling a multimegabyte "information resource" across the wire.
A solution is to use an HTTP "HEAD" request when you do the initial URI fetch. If it's an "other resource", the HEAD return will be a 303 and contain redirect that you want in the "Location" header, and that's all you need. If not, the 200 result will contain the content type and possibly even the size, which is what you need to know before you GET it.
So .. the problem that "hasPDF" is meant to address might be addressable by the crawlers just being a bit smarter about how they browse the semweb.
_______________________________________________
If you have received this transmission in error please notify us immediately by return e-mail and delete all copies. If this e-mail or any attachments have been sent to you in error, that error does not constitute waiver of any confidentiality, privilege or copyright in respect of information in the e-mail or attachments. Please consider the environment before printing this email.
-- --------------------------------------------------------------- Pete DeVries Department of Entomology University of Wisconsin - Madison 445 Russell Laboratories 1630 Linden Drive Madison, WI 53706 TaxonConcept Knowledge Base <http://www.taxonconcept.org/> / GeoSpecies Knowledge Base <http://lod.geospecies.org/> About the GeoSpecies Knowledge Base <http://about.geospecies.org/> ------------------------------------------------------------
On 06/01/2011, at 1:36 PM, Peter DeVries wrote:
Most groups now make their data available as an RDF dump which eliminated the need to crawl if you want to pull in a lot of data.
We supply this functionality via an OAI-PMH service. The "Protocol for Metadata Harvesting" is a standard way of asking for a list of ids or a list of actual records, limited by an optional "set" specifier and by start/end modification dates. Essentially: "What records do you have?" and "What's changed since last thursday?" If you pass set specifier to our service, we treat it as the prefix of the LSIDs that you want to limit your search to, allowing data harvesting to be done in manageable chunks. Our implementation does not perform especially well (I think the XSLT engine is the bottleneck). But that aside, OAI-PMH seems to be a sensible way for data stores to maintain mirrors of each other's data. Even just the list of ids changed since X id useful - you can remove them from your cache, and load them via linked data when required. See: http://www.openarchives.org/OAI/openarchivesprotocol.html http://biodiversity.org.au/oaipmh?verb=Identify Please do not send ListIdentifiers or ListRecords requests to this service without specifying a set that includes at least one character of the objectid part of the lsid. http://biodiversity.org.au/oaipmh?verb=ListIdentifiers&metadataPrefix=rdf&set=urn:lsid:biodiversity.org.au:afd.publication:11 It hasn't crashed for weeks now, and it would be nice to keep it that way for just a little longer <sob!>. _______________________________________________ If you have received this transmission in error please notify us immediately by return e-mail and delete all copies. If this e-mail or any attachments have been sent to you in error, that error does not constitute waiver of any confidentiality, privilege or copyright in respect of information in the e-mail or attachments. Please consider the environment before printing this email.
Hi Paul, This looks like a good API, but it is yet another API. There are at least four ways people tell the world about their linked data. 1) Set it up so it can be crawled 2) Publish a Semantic SiteMap. 3) Expose a void.rdf file 4) Add it to the CKAN package site. I do all of these and that does not count all the various GNI, GBIF, EoL, Digger etc. API's. I don't mean to say that one of these is better than the others. There are advantages to each - but there are simply too many. Respectfully, - Pete On Wed, Jan 5, 2011 at 9:05 PM, Paul Murray <pmurray@anbg.gov.au> wrote:
On 06/01/2011, at 1:36 PM, Peter DeVries wrote:
Most groups now make their data available as an RDF dump which eliminated the need to crawl if you want to pull in a lot of data.
We supply this functionality via an OAI-PMH service. The "Protocol for Metadata Harvesting" is a standard way of asking for a list of ids or a list of actual records, limited by an optional "set" specifier and by start/end modification dates. Essentially: "What records do you have?" and "What's changed since last thursday?"
If you pass set specifier to our service, we treat it as the prefix of the LSIDs that you want to limit your search to, allowing data harvesting to be done in manageable chunks.
Our implementation does not perform especially well (I think the XSLT engine is the bottleneck). But that aside, OAI-PMH seems to be a sensible way for data stores to maintain mirrors of each other's data. Even just the list of ids changed since X id useful - you can remove them from your cache, and load them via linked data when required.
See: http://www.openarchives.org/OAI/openarchivesprotocol.html http://biodiversity.org.au/oaipmh?verb=Identify
Please do not send ListIdentifiers or ListRecords requests to this service without specifying a set that includes at least one character of the objectid part of the lsid.
It hasn't crashed for weeks now, and it would be nice to keep it that way for just a little longer <sob!>.
_______________________________________________
If you have received this transmission in error please notify us immediately by return e-mail and delete all copies. If this e-mail or any attachments have been sent to you in error, that error does not constitute waiver of any confidentiality, privilege or copyright in respect of information in the e-mail or attachments. Please consider the environment before printing this email.
-- --------------------------------------------------------------- Pete DeVries Department of Entomology University of Wisconsin - Madison 445 Russell Laboratories 1630 Linden Drive Madison, WI 53706 TaxonConcept Knowledge Base <http://www.taxonconcept.org/> / GeoSpecies Knowledge Base <http://lod.geospecies.org/> About the GeoSpecies Knowledge Base <http://about.geospecies.org/> ------------------------------------------------------------
I should clarify that I used rdfs:seeAlso specifically because (as I understand it) it is one of the few RDF predicates where it is acceptable for the object to not be another RDF resource. See http://www.w3.org/TR/rdf-schema/#ch_seealso and various other discussions on the web as to why seeAlso was defined this way. Thus, it isn't clear to me that creating a "hasPDF" predicate is a good idea because it might send an uninformed client on a wild-goose chase for non-existent RDF. I believe that the idea behind seeAlso was that clients were on their own in figuring out the meaning of what they get as the result of following the seeAlso link. Steve Peter DeVries wrote:
I guess the question is do you want to use a generic seeAlso which most crawlers follow, vs some more specific predicate that says "here is the PDF"
My reluctance was more about minting my own vs. finding some other vocabulary which has a similar predicate.
With the *hasPDF* predicate it would be pretty easy to query for all species concepts that have a linked original description PDF etc.
I suspect that some standard predicate will eventually become accepted since it is very useful to have something more specific than foaf:Document.
Respectively,
- Pete
On Wed, Jan 5, 2011 at 6:54 PM, Paul Murray <pmurray@anbg.gov.au <mailto:pmurray@anbg.gov.au>> wrote:
On 06/01/2011, at 7:48 AM, Peter DeVries wrote:
Also, although I like a lot of what Steve says, I think that most existing crawlers expect that a seeAlso link is to some html, xml, rdf type thing and will not be able to handle a multi-megabyte PDF.
This is why I reluctantly minted the predicate "hasPDF"
Hmm. This is an issue with linkeddata: when you fetch a URI while crawling the semantic web, if it redirects, then it's an "other resource" and you get RDF. If not, then you are potentially pulling a multimegabyte "information resource" across the wire.
A solution is to use an HTTP "HEAD" request when you do the initial URI fetch. If it's an "other resource", the HEAD return will be a 303 and contain redirect that you want in the "Location" header, and that's all you need. If not, the 200 result will contain the content type and possibly even the size, which is what you need to know before you GET it.
So .. the problem that "hasPDF" is meant to address might be addressable by the crawlers just being a bit smarter about how they browse the semweb.
_______________________________________________
If you have received this transmission in error please notify us immediately by return e-mail and delete all copies. If this e-mail or any attachments have been sent to you in error, that error does not constitute waiver of any confidentiality, privilege or copyright in respect of information in the e-mail or attachments. Please consider the environment before printing this email.
-- --------------------------------------------------------------- Pete DeVries Department of Entomology University of Wisconsin - Madison 445 Russell Laboratories 1630 Linden Drive Madison, WI 53706 TaxonConcept Knowledge Base <http://www.taxonconcept.org/> / GeoSpecies Knowledge Base <http://lod.geospecies.org/> About the GeoSpecies Knowledge Base <http://about.geospecies.org/> ------------------------------------------------------------
-- Steven J. Baskauf, Ph.D., Senior Lecturer Vanderbilt University Dept. of Biological Sciences postal mail address: VU Station B 351634 Nashville, TN 37235-1634, U.S.A. delivery address: 2125 Stevenson Center 1161 21st Ave., S. Nashville, TN 37235 office: 2128 Stevenson Center phone: (615) 343-4582, fax: (615) 343-6707 http://bioimages.vanderbilt.edu
On 05/01/2011, at 4:33 PM, Steve Baskauf wrote:
From this standpoint, what Paul illustrated in his example of http://biodiversity.org.au/apni.taxon/118883 is exactly what I had in mind: a URI for the taxon/TNU/concept with RDF links to the URI for the name and the URI for the publication. The "fundamental problem" (recognized by Pete with his asterisk) is that most of these URIs don't yet exist and it would be counterproductive for a bunch of different people to start "minting" them on their own. I certainly don't have the interest or ability to do it and I doubt that Paul has time to create them all for the rest of us on the planet at biodiversity.org.au . This should be large scale/community effort. I was disappointed to see that although http://citebank.org seems to be positioning itself as such a large-scale effort, I can't see any evidence that it is planning to create "Linked Data-ready" URIs that are subject to content negotiation (or did I just miss it?). I think that is probably a mistake. Making a GUID that could be used in the LOD world doesn't force anybody to subscribe to the LOD model, but making a GUID that is not suitable for LOD will cause those who are interested in Linked Data to look elsewhere.
Workflow is an issue. If you want to use a common set of ids, then a person entering data must first go to that place where the common ids are curated and use that system to find/create the reference they are dealing with. If for any reason there is a problem, work stops. At the end of the day, any working system will most certainly have an internal, local table of citations. We intend to deal with this by exposing everything with a local id. But when we get around to matching our names (etc) with other systems. we will use an OWL "sameAs" declaration - declaring that the two URIs are different semweb names for the same real-world thing (not the same thing as taxonomic synonymy). As for "creating them all", I generate ids from the Australian Plant Names Index and the Australian Faunal Directory, which obviously each have an extensive list of publications and citations. You could quite happily use our URIs/LSIDs in your data ... or you could if I had a search interface written. Which is what Greg asked me to do, back before Christmas. I should be doing that now, instead of writing this. _______________________________________________ If you have received this transmission in error please notify us immediately by return e-mail and delete all copies. If this e-mail or any attachments have been sent to you in error, that error does not constitute waiver of any confidentiality, privilege or copyright in respect of information in the e-mail or attachments. Please consider the environment before printing this email.
Workflow is an issue. If you want to use a common set of ids, then a person entering data must first go to that place where the common ids are curated and use that system to find/create the reference they are dealing with. If for any reason there is a problem, work stops. At the end of the day, any working system will most certainly have an internal, local table of citations.
Dima at Eol.org Biodiversity Informatics and I have been trying to work out some automated way to do this. If you have submitted your list of names to the GlobalNames.org initiative there should be a URI that you can use to match that namestring to the identical namestring in a different data set. These URI's are still a little experimental, but the globalnames index is not so if you are not submitting your list of names there you should. IMHO :-) Eventually these URI's will allow you to link to the same namestring in a different data set by simply using the same algorithm to generate the URI. In theory, the GNI could then also return an RDF list of other contributing data sets that have that same name string. This would automatically allow you to create a URI for your namestring and find out what other data sets might contain relevant related data. **Avoiding the manual searching issue you mention above.* Yes, search interface ... I have the same problem and will get to it once the schema changing has settled down. For now you can find things in my knowledge base via the URL http://lsd.taxonconcept.org/fct/ For the entire LOD cloud you can try these sites: http://sindice.com/ http://lod.openlinksw.com/fct/ http://uriburner.com/fct/ Here is the info on how to contribute your names to the GlobalNames Index. https://github.com/dimus/gni/wiki/How-to-publish-your-scientific-names-list - Pete
We intend to deal with this by exposing everything with a local id. But when we get around to matching our names (etc) with other systems. we will use an OWL "sameAs" declaration - declaring that the two URIs are different semweb names for the same real-world thing (not the same thing as taxonomic synonymy).
As for "creating them all", I generate ids from the Australian Plant Names Index and the Australian Faunal Directory, which obviously each have an extensive list of publications and citations. You could quite happily use our URIs/LSIDs in your data ... or you could if I had a search interface written. Which is what Greg asked me to do, back before Christmas. I should be doing that now, instead of writing this.
_______________________________________________
If you have received this transmission in error please notify us immediately by return e-mail and delete all copies. If this e-mail or any attachments have been sent to you in error, that error does not constitute waiver of any confidentiality, privilege or copyright in respect of information in the e-mail or attachments. Please consider the environment before printing this email.
_______________________________________________ tdwg-content mailing list tdwg-content@lists.tdwg.org http://lists.tdwg.org/mailman/listinfo/tdwg-content
-- --------------------------------------------------------------- Pete DeVries Department of Entomology University of Wisconsin - Madison 445 Russell Laboratories 1630 Linden Drive Madison, WI 53706 TaxonConcept Knowledge Base <http://www.taxonconcept.org/> / GeoSpecies Knowledge Base <http://lod.geospecies.org/> About the GeoSpecies Knowledge Base <http://about.geospecies.org/> ------------------------------------------------------------
On 05/01/2011, at 8:01 AM, Peter DeVries wrote:
Users do not want to curate their own bibliographic databases and related RDF, they want to simply link to a globally unique, resolvable identifier for that citation.
Absolutely. There *is* a globally unique, resolvable identifier for publications: Digital Object Identifiers (DOI). It's a distributed, hierarchical system: organisations that publish works are assigned a root DOI and run a DOI server. Furthermore, DOIs can be assigned not simply to a publication, but to individual items in it, drilling down as far as you like. My impression is that DOIs mainly apply to things like journal articles: things that are being published today by publishers with an online presence. Many of our references here are CSIRO publications - I wonder if CSIRO publishing hosts a DOI resolver? A problem is that while given a DOI you can easily get the metadata for it, discovering the DOI for a publication is ... an effort. I imagine that another problem is homonyms: if two different publishers are producing editions of System Naturae, there will be different DOIs for it. Another issue is that if you want to cite a page of a journal, or better - a particular figure in the journal, and the publisher does not publish a DOI for that particular thing ... where do you go from there? You could host your own DOI server and assign your own DOIs .... but that rather defeats the purpose. There's no getting away from having a "microreference" field, allowing a human to fill in the gaps in the identifiers with free text. See: http://www.doi.org/ __________ The list of formally registered URN namespaces is here: http://www.iana.org/assignments/urn-namespaces/urn-namespaces.xhtml The ones potentially of interest - as far as I can see - with respect to serving as a globally unique citations are ISSN http://www.ietf.org/rfc/rfc3044.txt urn:ISSN:1560-1560 Identifies serials – periodicals, journals, newspapers ISBN http://www.ietf.org/rfc/rfc3187.txt URN:ISBN:0-395-36341-1 International Standard Book Number NBN http://www.ietf.org/rfc/rfc3188.txt URN:NBN:fi-fe19981001 National Bibliography Number. Identifiers given by the national libraries of various countries (Finland, in this case). These probably only go down to the "volume" level, but that's usually all you need for books. There are also urn namespaces for things like articles published by news organisations, audiovisual files, if you want to cite them. See: http://en.wikipedia.org/wiki/International_Standard_Serial_Number __________ Finally - identifying published documents and the places in them is a problem that librarians, in particular, are interested in. I'm sure that the worldwide library science community has some kind of handle on this, and it might be worthwhile to leverage their solutions. They seem to have a thing called an OCLC number (Online Computer Library Centre). eg: 17200046. I'm not sure how many scientific/taxonomic libraries feed data into the worldcat system. See: http://www.oclc.org http://www.oclc.org/research/ http://www.oclc.org/worldcat/web/ http://www.worldcat.org _______________________________________________ If you have received this transmission in error please notify us immediately by return e-mail and delete all copies. If this e-mail or any attachments have been sent to you in error, that error does not constitute waiver of any confidentiality, privilege or copyright in respect of information in the e-mail or attachments. Please consider the environment before printing this email.
Hi Paul, Yes, this works for recent publications but not for the older taxonomic publications that the BHL covers. Also, for recent articles that are part of PubMed their are Linked Data URI's. Zoobank has something that almost works but the are based on LSID's. - Pete On Wed, Jan 5, 2011 at 6:54 AM, Paul Murray <pmurray@anbg.gov.au> wrote:
On 05/01/2011, at 8:01 AM, Peter DeVries wrote:
Users do not want to curate their own bibliographic databases and related RDF, they want to simply link to a globally unique, resolvable identifier for that citation.
Absolutely. There *is* a globally unique, resolvable identifier for publications: Digital Object Identifiers (DOI). It's a distributed, hierarchical system: organisations that publish works are assigned a root DOI and run a DOI server. Furthermore, DOIs can be assigned not simply to a publication, but to individual items in it, drilling down as far as you like.
My impression is that DOIs mainly apply to things like journal articles: things that are being published today by publishers with an online presence. Many of our references here are CSIRO publications - I wonder if CSIRO publishing hosts a DOI resolver?
A problem is that while given a DOI you can easily get the metadata for it, discovering the DOI for a publication is ... an effort. I imagine that another problem is homonyms: if two different publishers are producing editions of System Naturae, there will be different DOIs for it.
Another issue is that if you want to cite a page of a journal, or better - a particular figure in the journal, and the publisher does not publish a DOI for that particular thing ... where do you go from there? You could host your own DOI server and assign your own DOIs .... but that rather defeats the purpose. There's no getting away from having a "microreference" field, allowing a human to fill in the gaps in the identifiers with free text.
See: http://www.doi.org/
__________
The list of formally registered URN namespaces is here: http://www.iana.org/assignments/urn-namespaces/urn-namespaces.xhtml
The ones potentially of interest - as far as I can see - with respect to serving as a globally unique citations are
ISSN http://www.ietf.org/rfc/rfc3044.txt urn:ISSN:1560-1560 Identifies serials – periodicals, journals, newspapers
ISBN http://www.ietf.org/rfc/rfc3187.txt URN:ISBN:0-395-36341-1 International Standard Book Number
NBN http://www.ietf.org/rfc/rfc3188.txt URN:NBN:fi-fe19981001 National Bibliography Number. Identifiers given by the national libraries of various countries (Finland, in this case).
These probably only go down to the "volume" level, but that's usually all you need for books.
There are also urn namespaces for things like articles published by news organisations, audiovisual files, if you want to cite them.
See: http://en.wikipedia.org/wiki/International_Standard_Serial_Number
__________
Finally - identifying published documents and the places in them is a problem that librarians, in particular, are interested in. I'm sure that the worldwide library science community has some kind of handle on this, and it might be worthwhile to leverage their solutions. They seem to have a thing called an OCLC number (Online Computer Library Centre). eg: 17200046. I'm not sure how many scientific/taxonomic libraries feed data into the worldcat system.
See: http://www.oclc.org http://www.oclc.org/research/ http://www.oclc.org/worldcat/web/ http://www.worldcat.org
_______________________________________________
If you have received this transmission in error please notify us immediately by return e-mail and delete all copies. If this e-mail or any attachments have been sent to you in error, that error does not constitute waiver of any confidentiality, privilege or copyright in respect of information in the e-mail or attachments. Please consider the environment before printing this email.
-- --------------------------------------------------------------- Pete DeVries Department of Entomology University of Wisconsin - Madison 445 Russell Laboratories 1630 Linden Drive Madison, WI 53706 TaxonConcept Knowledge Base <http://www.taxonconcept.org/> / GeoSpecies Knowledge Base <http://lod.geospecies.org/> About the GeoSpecies Knowledge Base <http://about.geospecies.org/> ------------------------------------------------------------
Chris, Here is another way of browsing the same thing from the LOD cloud. http://bit.ly/frtTa8 <http://bit.ly/frtTa8>- Pete On Tue, Jan 4, 2011 at 2:31 PM, Chris Freeland <Chris.Freeland@mobot.org>wrote:
Ooops, to clarify my very last example, we actually would support "Pallas 1767" if properly parsed:
* http://www.biodiversitylibrary.org/openurl?aulast=Pallas&date=1767&format=xml *<http://www.biodiversitylibrary.org/openurl?aulast=Pallas&date=1767&format=xml>
What we don't yet support & need to is linking at article citation level. That's where our newly (quietly) launched CiteBank http://citebank.orgcomes in, and what we're hoping to receive funding to expand. Chris ------------------------------ *From:* tdwg-content-bounces@lists.tdwg.org [mailto: tdwg-content-bounces@lists.tdwg.org] *On Behalf Of *Chris Freeland *Sent:* Tuesday, January 04, 2011 1:57 PM *To:* Peter DeVries; Steve Baskauf
*Cc:* tdwg-content@lists.tdwg.org *Subject:* Re: [tdwg-content] GUIDs for publications (usages and names)
Steve, Pete, et al.,
BHL has an OpenURL resolver that can accept a variety of input criteria & return matching records with responses in JSON (with or without callback), XML, HTML, or a direct link. Documentation is here: http://www.biodiversitylibrary.org/openurlhelp.aspx
And linked from our broader documentation here: http://biodivlib.wikispaces.com/Developer+Tools+and+API
Here's an example, referenced in the documentation, for querying on a monograph/book:
You can also query based on common abbreviations, like Sp. Pl.:
http://www.biodiversitylibrary.org/openurl?stitle=Sp.%20Pl.&date=1753&format=xml
MOBOT's Tropicos uses the OpenURL resolver to link to protologues, as in this example: http://www.tropicos.org/Name/2735114
With Tropicos we have an authority record for each journal or monographic title. We match Tropicos' TitleID to BHL's TitleID & use that as a more direct link to the appropriate reference, but still send collation & other info to get to the appropriate page, as in this link:
http://www.biodiversitylibrary.org/openurl?pid=title:626&volume=5&issue=&spage=244&date=1830
I know that this is insufficient for zoology & other natural sciences beyond botany, where we need to be able to support citations like "Pallas 1767", which may or may not be preparsed into appropriate fields. A known problem, for sure, and one that we're eager to address, pending funding from NSF.
Chris
Chris Freeland | Director, Center for Biodiversity Informatics | Missouri Botanical Garden 4344 Shaw Blvd. | St. Louis, Missouri 63110 | 314.577.9548
------------------------------ *From:* tdwg-content-bounces@lists.tdwg.org [mailto: tdwg-content-bounces@lists.tdwg.org] *On Behalf Of *Peter DeVries *Sent:* Tuesday, January 04, 2011 1:33 PM *To:* Steve Baskauf *Cc:* tdwg-content@lists.tdwg.org *Subject:* Re: [tdwg-content] GUIDs for publications (usages and names)
Hi Steve,
I have been lobbying the BHL for this for some time. Most recently in this blog post.
http://www.taxonconcept.org/taxonconcept-blog/2010/8/5/why-linked-open-data-...
What I have realized is that, for many works that are out of copyright, Google books has already scanned and converted them to PDF.
You can use these, even extract the relevant PDF pages as long as you keep the Google watermark.
This is what I have done for the Cougar.
http://lod.taxonconcept.org/ses/v6n7p.html
For more recent works you may be able to link to the article PDF. As in this spider example.
http://lod.taxonconcept.org/ses/2mqjL.html
We also need a URI for to uniquely identify authors and in the absence of a better solution, I have been using, and in some cases creating, entries in Wikipedia which currently has over 5,000 taxonomic author profiles.
This results in usable RDF via DBpedia. As you can see in the RDF in this example.
http://lod.taxonconcept.org/ses/v6n7p.rdf
And in the Knowledge Base < http://lsd.taxonconcept.org/describe/?url=http%3A%2F%2Flod.taxonconcept.org%2Fses%2Fv6n7p%23OriginalDescription>
That said, I have also been experimenting with this.
http://lod.taxonconcept.org/people/sci_people_1700.rdf
About: Carl Linnaeus http://bit.ly/gLgElf
- Pete
On Mon, Jan 3, 2011 at 7:47 PM, Steve Baskauf < steve.baskauf@vanderbilt.edu> wrote:
I was reviewing some of the previous posts on taxon name usages in an attempt to understand them better. I have learned that the Global Names Index is an attempt to catalog taxon names and that it is possible to generate a URI that points to a name there. Is there a parallel effort to do the same thing for literature references? In other words, if I want to describe the TNU: Andropogon virginicus L. sec. Radford et al. (1968) I think I could find a URI GUID for the name Andropogon virginicus . But is there some place where I could find a unique identifier, or better a URL, or best a URI providing RDF/XML for Linnaeus 1753 (the author and publication for the name) and for Radford et al.1968 (the author and publication that expresses the usage I'm intending).
I suppose that this question has previously been answered in the in the many posts on taxon names, concepts, etc. However, since usually my brain goes numb and my eyes glaze over in those threads, I probably missed it.
Steve
-- Steven J. Baskauf, Ph.D., Senior Lecturer Vanderbilt University Dept. of Biological Sciences
postal mail address: VU Station B 351634 Nashville, TN 37235-1634, U.S.A.
delivery address: 2125 Stevenson Center 1161 21st Ave., S. Nashville, TN 37235
office: 2128 Stevenson Center phone: (615) 343-4582, fax: (615) 343-6707 http://bioimages.vanderbilt.edu
_______________________________________________ tdwg-content mailing list tdwg-content@lists.tdwg.org http://lists.tdwg.org/mailman/listinfo/tdwg-content
-- --------------------------------------------------------------- Pete DeVries Department of Entomology University of Wisconsin - Madison 445 Russell Laboratories 1630 Linden Drive Madison, WI 53706 TaxonConcept Knowledge Base <http://www.taxonconcept.org/> / GeoSpecies Knowledge Base <http://lod.geospecies.org/> About the GeoSpecies Knowledge Base <http://about.geospecies.org/> ------------------------------------------------------------
-- --------------------------------------------------------------- Pete DeVries Department of Entomology University of Wisconsin - Madison 445 Russell Laboratories 1630 Linden Drive Madison, WI 53706 TaxonConcept Knowledge Base <http://www.taxonconcept.org/> / GeoSpecies Knowledge Base <http://lod.geospecies.org/> About the GeoSpecies Knowledge Base <http://about.geospecies.org/> ------------------------------------------------------------
participants (8)
-
 Chris Freeland
Chris Freeland -
 Dean Pentcheff
Dean Pentcheff -
 Paul Murray
Paul Murray -
 Peter DeVries
Peter DeVries -
 Richard Pyle
Richard Pyle -
 Roderic Page
Roderic Page -
 Steve Baskauf
Steve Baskauf -
 Tony.Rees@csiro.au
Tony.Rees@csiro.au