
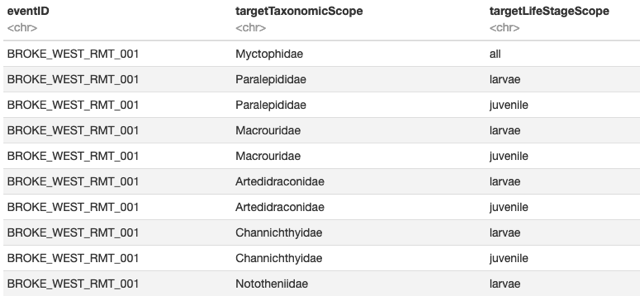
Hi all, I wanted to send this again because I did not get the opportunity to ask my questions nor did I get any answers (except the GitHub issue<https://github.com/tdwg/hc/issues/103>) and I have put in ample amount of time in this. My questions here maybe relevant for the publishing guide that Kate is working on. OBIS underwent some restructuring earlier this year and there is an opportunity for me to present this to the OBIS Data Coordination Group in the future. I understand the importance of the paper. However, to be fair, I sent this email since mid may … can I at least have a meeting to ask these questions please? Thank you. Sincerely Ming Begin forwarded message: From: Yi-Ming Gan <ymgan@naturalsciences.be> Subject: BROKE-WEST dataset mapped to ratified Humboldt terms + Questions Date: 14 May 2024 at 15:45:55 CEST To: Humboldt Core TG <tdwg-humboldt@lists.tdwg.org> Hi all, I have finally mapped the BROKE-WEST dataset to the ratified Humboldt terms. I mapped it in a different way after chatting with John last year. I am trying to explore if using combinations of target scope per row in Humboldt table will make more sense instead of using pipe separated values (see below): [Screenshot 2024-05-14 at 14.17.42.png] I don’t know if I am understanding things well. I feel it is a little confusing - each row in the Humboldt extension file seems to be conflating the Scopes and Event. For example the value of hasNonTargetTaxa for each row above has to check whether Taxon in Occurrences exist in ALL targetTaxonomicScope where eventID == “BROKE_WEST_RMT_001” (multiple records in Humboldt table) … I also have multiple questions when performing this mapping which I documented in the Rmarkdown here<https://raw.githack.com/biodiversity-aq/humboldt-for-eco-survey-data/main/src/create-humboldt-ext.html>. Overall, I find it very challenging and complicated (took me 2 full days with the help of chatgpt) to write the code to fill in the boolean values (is___, has____) … I would love a third pair of eyes to help me to look at this. Is anyone willing to look at my work with me please? I am fine with walking you through at our usual meeting times. GitHub repo: https://github.com/biodiversity-aq/humboldt-for-eco-survey-data This is the only script that I worked on these two weeks: https://github.com/biodiversity-aq/humboldt-for-eco-survey-data/blob/main/sr... Humboldt Extension generated by the script: https://github.com/biodiversity-aq/humboldt-for-eco-survey-data/blob/main/ou... @John, I saw that the new data model<https://docs.google.com/document/d/1eGD69E-KzqdOcjh637iPrp1gv_J55CM2VPAjD1PSu_w/edit?usp=sharing> is updated - is there some instructions available somewhere where I can test the Publishing and Conceptual model please? Thank you so much!! Cheers Ming <https://www.naturalsciences.be/>[clip_image002.png] Yi-Ming Gan Institute of Natural Sciences Operational Directorate Natural Environment Data manager - Antarctic Biodiversity Portal T +32 (0)2 627 42 77 Rue Vautier 29 Brussels 1000 Belgium
{kind=link}
{kind=link}