Steve,
Our information system requirements here at CANB have resulted in a data model that looks pretty-much like Rich's diagram1 (except we choose, as you suggest, to sink location into event - though for the reason that each event will normally result in a unique description of its locality) but we do have applications that prefer to view these data as you have modelled it at diagram2. Interestingly the former is very close to the ASC data model (Blum 199? which I could not find online) and the latter, very like ABCD (if you collapse individual to an instance of occurrence). Neither of these look much like Darwin Core Archive format which requires one to collapse everything to properties of an occurrence.
In our system very few properties have definitions that correspond to Darwin Core terms. Even our classes have different definitions. When we interchange data between Australian herbaria we choose to stick with hispid
which provides for more precise definitions and tighter controlled vocabularies than are possible with Darwin Core (eventually I would hope that these narrower terms might be mapped vertically with Darwin Core within a TDWG knowledge organisation system implemented using broader standards) but this does not prevent us mapping local vocabularies into darwin core for the purpose of delivering data to GBIF, the ALA or any network that chooses to to accept data in a more generic state. In many cases, especially when we consider individual values for any given term, this results in information loss but as this is essentially one way traffic its not our loss.
So for the benefit of those consumers of generic TDWG product we try to provide services delivering DwC, ABCD, HISPID, TCS, TDWG-RDF, etc as expected. Thats what our clients expect and it works for us because it simplifies the development of local API.
In our world occurrence is an abstraction and one of the hardest things to deliver using DwC. It simply does not exist as a distinct object within our information system. As a relation using gathering and taxon it is essentially an ephemeral thing. Sooner or later it will change … same identifiers for a different taxon at the same locality. These data are also highly repetitive and a dilemma we face in delivery is how to choose which values to omit when mapping to Darwin Core Occurrence.
The point is that in Darwin core we have a standard for communication at a very generic level. The fact that ones "individual" maps to DwC as "occurrence" or that we have 200 million specimen annotations that cannot be mapped to concepts or that I must choose one of 27 unique identifiers for objects resulting from a single gathering to construct a DwC record does not prevent us from choosing to model the world in a way that best suits the our particular requirements or delivering data into the Global network using Darwin Core.
When comes to RDF representations there is a simple rule that we use well known forms wherever possible. But here we have the advantage of being able to incorporate generic vocabulary within more expressive content. To say what we mean without excluding consumers with only the core vocabulary.
greg
Rich,
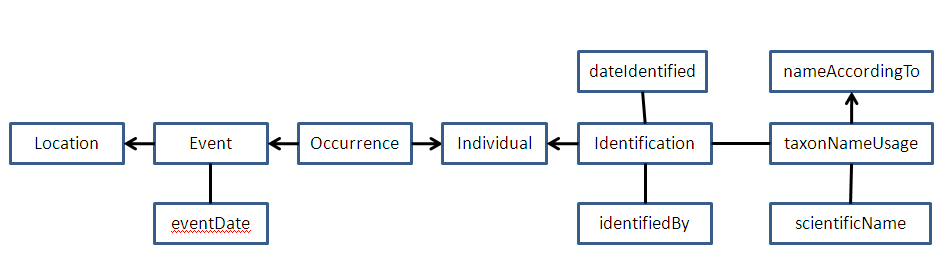
Thanks for the great summary diagram and even more amazing that it was made under mushed brain conditions. Hopefully you've gotten sleep since then. Unfortunately, when I tried to look at it I had some problems with line breaks. I've tried to recreate your diagram at
http://bioimages.vanderbilt.edu/pages/rich-diagram1.gif
Please correct me if I didn't get it right. My arrow-drawing utility put the arrow heads on the other end of the lines, but I think the arrows still maintain the "many to one" relationships you were trying to represent. I also replaced eventTime with eventDate since the latter is a broader term that also can include the time.
In principle, I agree with this diagram to the left of taxonNameUsage completely. (I still need clarification about a few things on the right end.) My main reason for using determination as a term rather than identification is because it is not ambiguous to refer to the person doing the identifying as the determiner, whereas referring to that person as the "identifier" creates confusion between that person and the identifying string for resources (as in "persistent identifier"). So if we agree that determination, annotation, and identification all mean the same thing (namely an instance of the dwc:Identification class), I'm happy to just use the term "identification". For the person doing it, I guess dwc:identifiedBy would be the best term although it's a bit awkward in regular speech so I may slip and still say "determiner".
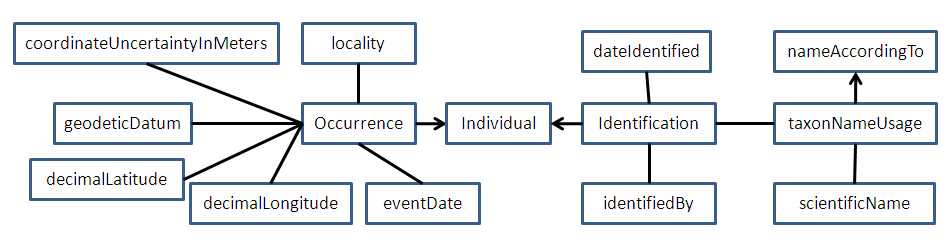
Although I agree in principle that there can be many occurrences at an Event and many events at a Location, I think there are two practical reasons why it may be better to assign separate eventDate and Location metadata to each Occurrence. The first is that it makes the database structure simpler. As Markus has already noted, we really would prefer for the database to be as "flat" as possible. When I look at the terms listed in the DwC term page (http://rs.tdwg.org/dwc/terms/index.htm) under Event, the most important one that I see which everyone should be providing is eventDate. The rest I would pretty much consider optional and as a shortcut Rich's diagram could be collapsed to make them direct properties of the Occurrence. The second reason involves the practical matter of defining a Location. I will note that my thinking about this has been deeply influenced by a previous discussion on the topic from 2008-2009 summarized at http://www.sernec.org/files/summary-of-discussion.pdf on p.78-84. I don't think most people will want to wade through all of that text, so I'll just sum it up here. Somebody (I think it might have been Debbie Paul at Morphbank) suggested to me that we really have an intrinsically globally unique identifier for Location. It's the combination of dwc:decimalLatitude and dwc:decimalLongitude along with dwc:coordinateUncertaintyInMeters to establish precision and dwc:geodeticDatum to establish the reference system. (If we like geo:lat and geo:long, then the reference system is implied and we are down to three terms to unambiguously define a Location and its uncertainty. For the benefits of humans, a Locality description is probably also beneficial. Also, elevation and depth might be provided, although at least in theory elevation could be calculated with a sufficiently good digital elevation model). I will grant that we don't have this information for a lot of old records, but based on the massive efforts to geolocate specimens, I would say it's pretty clear that this is what we would like to have if we could get it. I certainly hope that there aren't any serious collectors, observers, and live organism photographers who aren't by this point trying to record this information as they establish new Occurrence records. If you look at all of the Location terms on the dwc list, most of the other terms are either concessions to the fact that we don't have what we want (e.g. the "verbatum" terms), things we could generate using a computer program if we were clever (like stateProvince, county, etc. - I know at least Mike Giddens has succeeded in doing this), ways of indicating how we got lat and long from old records (e.g. georefererenceSources), or methods to define larger scale Locations that aren't points (e.g. footprintWKT). I think it is safe to say that in the future (if not now already), many or most Events associated with Occurrences will have an associated button click (on a GPS receiver, camera phone, or GPS enabled camera) that will automatically generate dwc:eventDate, dwc:decimalLatitude, dwc:decimalLongitude (with geodeticDatum=WGS84) and maybe coordinateUncertaintyInMeters. Thus designing a system that requires that these time/space snapshots be grouped together into artificial "Locations" is really counterproductive when those data are now generated and can be associated with Occurrences automatically. I don't know if Greg Riccardi of Morphbank is following this thread or not. If so he may want to comment on this issue based on practical experience at Morphbank. When the Morphbank system was set up, it required the creation of a separate Location record which was assigned a unique Morphbank identifier. Specimens were then linked to this Location. What ended up happening was that each Specimen having GPS metadata ended up being assigned to its own separate Location even if it was 20 meters from another specimen. In effect, each Occurrence record ended up having its own decimalLatitude/decimalLongitude record anyway. So the system ended up being more complicated than necessary.
As I said, I agree in principle with the left side of Rich's diagram. Taking the practical considerations I just mentioned into account, I would simplify the diagram as
http://bioimages.vanderbilt.edu/pages/rich-diagram2.gif
Superficially, it looks more complicated, but I've gotten rid of several "one to many" relationships and enthroned Occurrence at its accustomed place in the center of the universe (or at least the center of the left side of the diagram). I don't have any philosophical objections to people structuring their data according to Rich's original diagram and the existing Darwin Core terms certainly make it possible to do so (well except for the Individual thing). However, I submit that many people will find it simpler (and easier to use tools like Darwin Core Archives) if they use the flatter structure that I have in the revised diagram.
I will save my questions about the right side of Rich's diagram for later.
Steve
Richard Pyle wrote:All, I'm in Stockholm, and right now it's 10am in Hawaii, and I've effectively been awake since 7pm Hawaii time -- so my brain is a bit mush. But I'll take a chance and comment anyway.I will leave up to the taxonomy people the different things would be connected to the species concept and how all of their lines would be connected.In my mind the "fully-normalised" (sensu Döring) relationship graph is something like this (notation is [One]--<[Many]; [One]--[One]) (Be sure to view as a fixed-width font, like Courier): [identifiedBy] | [Location]--<[Event]--<[Occurrence]>--[Individual]--<[Identification]--[Taxo nNameUsage]>--[nameAccordingTo] | | | [eventTime] [dateIdentified] [scientificName] I'm following what I *think* Steve defined for [Individual], which is that it can be either a single individual organism or a defined set of organisms (e.g., up to at least a population). So, an Occurrence is the intersection of an Individual and an Event. An Event is a Location+Time[+other metadata]. Each Event may have multiple Occurrences (i.e., one for each distinct Individual at the same Location+Time). Also, an Individual may have multiple Occurrences (one for each Event at which the same Individual was documented). An Individual may have multiple Identifcations. I make no distinction between "Identification" and "Determination" (nor do I make a distinction between the first identification and subsequent identifications). I slightly prefer "Identification", because "Determination" seems to imply that there is a correct answer, whereas "Identification" (to me, anyway), implies an opinion. Steve, I didn't quite follow how you were distinguishing these two terms -- so if you have a clear reason for distinguishing them, I'd like to understand it better. A single Identification should, in my mind, always join a single individual with a single "TaxonNameUsage" instance. I'm not 100% sure how TaxonNameUsage maps in DwC. I *think* it's an instance of a dwc:Taxon, as most of the core attributes of a TNU (acceptedNameUsage[ID], parentNameUsage[ID], originalNameUsage[ID], scientificName, taxonRank) are represented as terms in the Taxon Class. But I'm a little fuzzy on whether a "taxonID" maps directly to a TNUID, or if a TNUID more correcly maps to taxonConceptID.The determination would have any of the properties that are terms listed in the dwc:Identification class (identifiedBy, dateIdentified, identificationReferences, identification Remarks, identificationQualifier, and typeStatus). Some properties like dateIdentified and identificationReferences would be string literals and others (especially identifiedBy) should probably be GUIDs but could be literals if they had to be.I agree with what Steve wrote above. However, I'm uncomfortable with Markus' suggestion of treating dwc:nameAccordingTo as a property of an Indentification -- even as a shortcut. I think this is a bit dangerous. If there is no TaxonID instance (aka "TaxonNameUsage" in my diagram above) available to link the Identification to, then I would suggest using identificationReferences as the shortcut. But that would still force you to attached scientificName directly to the Identification instance, which I think is also unwise. I'd rather the Best Practice be to "manufacture" a place-holder dwc:Taxon instance (if a proper one doesn't already exist in the content source), and apply the scientificName property to that Taxon instance, rather than directly to an Identification. I know it's often short-hand to attach the scientificName directly to the Occurrence instance; but I actually feel less uneasy about that, because it is much more obviously a shortcut. But if you're going to the trouble to provide an instantiated "Identification", then you ought to anchor it to a Taxon instance (manufactured or real). But, I guess as Greg said in his post, it may not really matter, as in the long run, we'll probably be able to make inferences about the proper Individual<-->TaxonConcept mapping, even when it's not explicitly documented.1. The original label identifies the species as Juncus diffusissimus. However, there is no indicator as to who originally identified it or when. My assumption is that it was the collector (Glen N. Montz) but I don't really know that. Do I assume that, or list the original determiner as "unknown"?I would make no assumptions about who was the identifiedBy person. Instead, in these cases I handle these cases by either going with "Unspecified", or, in some cases (when I have confidence), something like "Bishop Museum Staff Member". Often I can deduce the identifier with some degree of confidence, but usually I don't have the time to do this. The dateIdentified can either not be provided, or set as some range (e.g., at the very worst, on or after the eventDate/eventTime, and before today). This is why I think that identification tags ("annotations" sensu Baskauf) can be "documentation sources for TNUs. In the web example given by Steve, we have an idetification as follows: Juncus diffusissimus Buckl. Determined by: L. Urbatsch Determination date: 2009 Completely independantly of the specimen itself, we can infer from the tag that: - Sometime between 1 Jan 2009 and 31 Dec 2009, L. Urbatsch regarded the genus "Juncus" as valid. - Sometime between 1 Jan 2009 and 31 Dec 2009, L. Urbatsch regarded the species epithet "diffusissimus" [of Buckl.] as a valid species, placed within the genus "Juncus". Thus, we have at least two implied TNUs from this identification, which was documented on a piece of paper that happens to be fixed to LSU-BR 39823. The Identification instance would link the Individual (manifest as a specimen, in this case) to the TNU of "[Juncus] diffusissimus Buckl. sec L. Urbatsch 2009". The nameAccordingTo would be "L. Urbatsch 2009". This may seem redundant to have "L. Urbatsch 2009" in both the nameAccordingTo attribute of thr Taxon instance, and in the identifiedBy & dateIdentified attributes of the Identification instance -- but the fact remains they are fundamentally different pieces of information. One establishes an instance of an (implied) taxon concept, and the other establishes the placement of LSU-BR 39823 within that taxon concept circumscription. Eventually, a third party may be able to deduce (perhaps through a suite of other, external information) a RelationshipAssertion that maps the TNU "[Juncus] diffusissimus Buckl. sec L. Urbatsch 2009" to some other, perhaps published and well-defined taxon concept (of the same or different name). Also, if there are 100 specimens in the collection that L. Urbatsch identified as "Juncus diffusissimus Buckl." in 2009, then anchoring all 100 Identification instances to the one TNU, allows all of those specimens to inherit the mapping of the one "[Juncus] diffusissimus Buckl. sec L. Urbatsch 2009" TNU instance to some other better-defined taxon concept. I know this is a lot of stuff to keep in one's head at the same time -- but as cumbersome as it seems, I am conviced it can be packacged into a relatively straightforward and intuitive user UI, and modelling it this way improves the utility of the data (maybe dramatically) in the long run.2. Do we draw a distinction between the initial identification andsubsequent annotations?I think the answer should be "no" and that's why I refer to bothgenerically as "determinations". I agree.3. There is really no indication given on the annotation labels as to many of the things that we would like to know, such as the concept they had in mind, any source they used (if any), or the reason why they did the annotation. So how does one connect the name that they applied to the determination when there is no indication of the concept?As I said in an earlier post, the single most important way to reduce taxonomic ambiguity is to try to capture (or confidently deduce) the source (=mapping to taxon concept). But if it can't be done, then it can't be done -- so I'm inclined to establish a "place-holder" dwc:Taxon instance, with no nameAccordingTo, and no other metadata besides the scientificName.Is this just something we can't do for old annotations and just something that we try to do from this point forward?Probably.4. The last question is one that I really want to some opinions about. It seems to me that there are a number of reasons why one would apply a determination.Hmmm....I don't think this is really useful information. I don't undersatand how you would use this information ina machine-processing sort of way. An Identification is an Identification. In some cases, the Identifier may not even be aware of the previous identification, and so we can necessarily infer there was a particular "reason". And even if there is a reason, how doe we use that information? What if there is more than one reason (i.e., if we are restricted to a controlled vocabulary)? As far as I'm concerned, the Identifications should stand as they are. If needed people can annotate the Identification instances; but I don't see the value in machine-processing these things. Also:Finally, a single determiner might apply several determinations to one individual and indicate in each determination the concept intended (i.e. if you subscribe to Cronquist, you'd call it X; if you like Radford's book, you'd call it Y; if you like Weakley's treatment, you'd call it Z).YIKES! I don't like the idea of loading all that information on an Identification instance. If the person wants to make this sort of assertion, then they should establish the appropriate relationshipAssertion instances among the various taxonConcepts cited. Damn. Now my head is really tired. And so is the rest of me.... Aloha, and g'night.. Rich .
-- Steven J. Baskauf, Ph.D., Senior Lecturer Vanderbilt University Dept. of Biological Sciences postal mail address: VU Station B 351634 Nashville, TN 37235-1634, U.S.A. delivery address: 2125 Stevenson Center 1161 21st Ave., S. Nashville, TN 37235 office: 2128 Stevenson Center phone: (615) 343-4582, fax: (615) 343-6707 http://bioimages.vanderbilt.edu
------
If you have received this transmission in error please notify us immediately by return e-mail and delete all copies. If this e-mail or any attachments have been sent to you in error, that error does not constitute waiver of any confidentiality, privilege or copyright in respect of information in the e-mail or attachments.
Please consider the environment before printing this email.
------
_______________________________________________
tdwg-content mailing list
tdwg-content@lists.tdwg.org
http://lists.tdwg.org/mailman/listinfo/tdwg-content
{kind=link}
{kind=link}